- はじめに
- 現状の実装と課題: 不整合データの混入による手戻り
- 対応方針: PR 時点でデータ不整合を検出する
- 実装
- GitHub Actions で dbt seed と test を行う
- 導入結果
- さいごに
- 参考文献
はじめに
こんにちは、BI チームの田辺です。この記事はGunosy Advent Calendar 2023の 12 日目の記事です。 前回の記事は UT さんのコスト削減できる箇所をひねり出すでした。
さて、今回は dbt seed を使って csv ファイルを DWH へ格納させる試みについて紹介いたします。
普段はデータアナリストとして業務を行っており、dbt seed と GitHub Actions を使った実装は今回が初めてです。稚拙な文章であることをあらかじめご了承ください。
現状の実装と課題: 不整合データの混入による手戻り
社外データや社内のスプレッドシート管理された数値などといったデータと、DWH 内のデータを突合して確認したいシーンはたびたび発生します。今回はその一例として、予算データを例に上げます。
弊社では業績予想や社内予算の策定をスプレッドシートで行っています。社内で広く予実管理を行いやすいように、予算データを整形し DWH へ格納しているのですが、これまで以下のような手順を踏んでいました。
- 確定した予算データをテーブルフォーマットに整形し、csv ダウンロード
- DWH に対応したディレクトリに csv ファイルを追加する PR を作成する
- マージする
- workflow により追加された csv ファイルのデータが予算テーブルに union される
- テーブルの動作確認を行いながら dev → stg → prd 環境へと拡大する
データ更新を自動で行う仕組みはできていたのですが、手順 1 のデータ整形のタイミングで
- N/A などのエラー値や空行の混入
- データ型の不一致
- 値の参照ミス
などといったヒューマンエラーがたびたび発生していました。
追加するレコード数が多い場合、こういった凡ミスに気づかず dev, stg 環境にマージ後に発覚 → 再度 PR を作成 → Review → 動作確認 といったフローを取ることが多くありました。 この作業が四半期ごとに × 予算を策定する指標の数だけ発生するため、地道な修正作業に少なくはない時間を費やしていました。
今回、このような凡ミスを PR マージ前に事前に潰すことを目指し、dbt seed と GitHub Actions を用いた仕組みを作りました。
対応方針: PR 時点でデータ不整合を検出する
CI 環境で dbt が使えるようになった
弊社の DWH において変換処理を dbt に移行するプロジェクトが進められてきました。
移行作業の際に稼働中のデータ基盤にデグレを生まないために、 CI 環境内で dbt を用いたデータテストを可能にする GitHub Actions のワークフローを用意していました。 今回、この仕組みの上に乗ることで CI 時点で dbt seed で取り込んだデータに対するテストを実現させました。
dbt seed とは
dbt コマンドの一つで、csv ファイルや json ファイルを DWH にテーブルとして読み込む機能です。 docs.getdbt.com
今回 dbt seed を使うことで次の 2 点を期待しました。
テーブル作成時に失敗するようなエラーデータが含まれていると create table 実行で失敗するため、事前にミスに気づきやすい
dbt model などと同様に dbt test を使ったテストが書けるため、データの中身に対しても一定の品質を担保しやすい *1
方針
最終的な状態として、大まかに以下の流れができることを目指します。
- DWH へ格納したい csv ファイルを含んだ PR を作成する
- GitHub Actions に作成したジョブで以下が行われる
- 対象ファイルに対して
dbt seedを実行し、テーブルを作成する- この時点でテーブル化できないデータ不整合があるとエラーが表示される
- 作成されたテーブルに対して
dbt testを実行し、データの中身に問題がないかテストする- primary key 制約を満たしていない場合エラーが表示される
- 対象ファイルに対して
- CI でエラーが出た箇所を修正する
- すべての CI が成功したらマージ可能になる
実装
csv ファイルの配置
予算データを整形した csv ファイルを seeds/{DB名}/ 配下に置きます。
dbt
├── dbt_project.yml
├── macros
├── models
├── seeds
├── budget
├── 2023_1Q_v1.csv
├── 2023_1Q_v2.csv
├── ..
└── tests
この状態で dbt seed を実行すると、 csv ファイルから自動でカラムとそのデータ型を把握し、create table が実行されます。
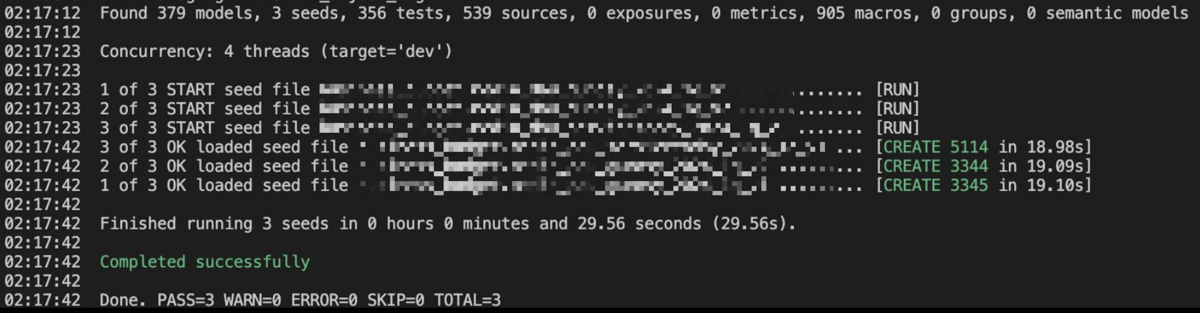 もし csv ファイルのデータに問題があった場合は create table の実行に失敗し、エラーを吐いてくれます。
例えばスプレッドシートの表示形式設定ミスにより、 csv ファイルのとある数値のカンマ表記が残っていたとします。
もし csv ファイルのデータに問題があった場合は create table の実行に失敗し、エラーを吐いてくれます。
例えばスプレッドシートの表示形式設定ミスにより、 csv ファイルのとある数値のカンマ表記が残っていたとします。
date,budget,created_date 2024-06-01,12,345,2024-06-01 2024-06-02,12355,2024-06-01 2024-06-03,13365,2024-06-01 ...
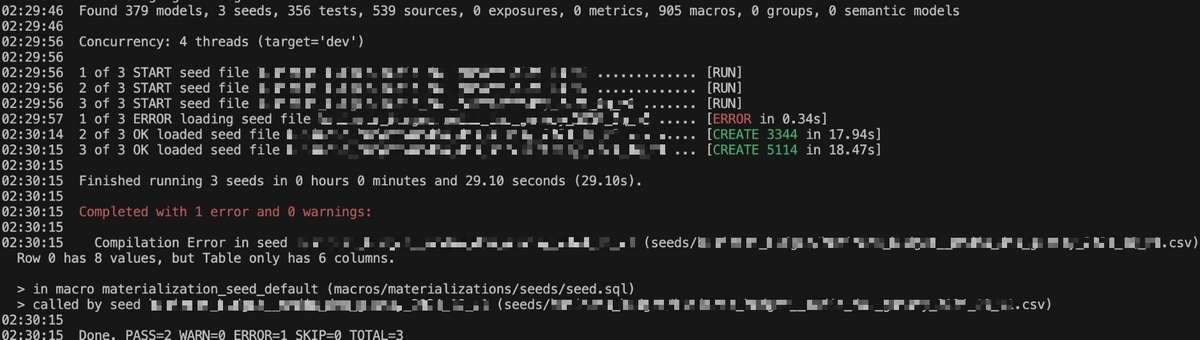
この状態で dbt seed を実行すると次のようなエラーが表示されます。エラーからカラム数とデータの列数がズレていることが分かるので、カンマに注目して修正箇所を探すことができます。
正常に dbt seed が実行されると DWH 上にシードテーブルが作成され、dbt model から参照できるようになります。
select * from {{ ref('budget__2024_1Q_v1') }}
プロファイル設定
dbt_project に seeds の設定を追加する
dbt_project.yml にはプロジェクトの設定(データベースへの接続情報やモデルのファイルパスなど)が記述されています。 seeds のデフォルト設定を変更したり、オプション設定を追加する場合は dbt_project.yml に記述します。
今回は次のような設定を追加しました。
seeds: target_project: +full_refresh: true budget: +schema: "budget"
+full_refresh: true は dbt seed の実行時に既存のシードのテーブルを一度削除してから再度テーブルを作成するオプション設定です。(CLI から dbt seed --full-refresh でも実行できます)
同じ名前のテーブルを複数回作成しようとすると、既存テーブルを上書きしないようにエラーが出ます。full_refresh オプションを使うことでこのエラーを回避することができます。
+schema: "budget" ではシードのテーブルのスキーマを指定しています。budget という key はフォルダ構造に依存して決まっており、ここでは seeds/budget と対応します。
結果、このディレクトリ配下のデータについては budget スキーマに作成されます。
なお、seeds について設定を記述していない場合はデフォルトのシードデータの読み込み先として data/ もしくは seeds/ ディレクトリが使用されます。
シードでロードするテーブルの設定を追加する
次にシードでロードしたテーブルに対して dbt test を行うために、テーブルのプロファイル (例: seeds/2024_1Q_v1.yml )の tests セクションでテスト内容を指定します。
今回は date カラムと created_date カラムの組み合わせがユニークになっているかを確認するテストです。
version: 2 seeds: - name: budget__2024_1Q_v1 description: | 予算 2024年度1Q v1 config: alias: 2024_1q_v1 tests: - unique_combination_of_columns: combination_of_columns: - date - created_date columns: - name: date description: | 日付 data_type: date - name: budget description: | hogehoge指標の予算値 data_type: int - name: created_date description: | 予算データ反映日 data_type: date
- テストの内容は
tests/配下に {test_name}.sql で記述します。例えば次のようなユニークなレコード数を確認するテストがあります。
ここまでで、dbt seed によって取り込んだデータに対するテストを実行できるようになりました。
GitHub Actions で dbt seed と test を行う
次は同じ内容を CI 環境で実行できるようにします。 すでに整備されている以下の 3 つのジョブに、dbt seed と作成されたテーブルに対する dbt test の実行をするジョブを追加します。
- Continuous Integration (CI)
- plan-catalogs: CLI による差分検知を実行するジョブ
- audit-catalogs: stg 環境上にあるデータを用いて、PR 前後のモデルを比較し、変更があったモデルへのテストを行うジョブ
- Continuous Delivery (CD)
- apply-catalogs: plan-catalogs の結果を受けて変更を反映するジョブ
dbt seed の実行は csv ファイルの変更を伴わない PR に対して実行する必要はないため、ジョブが発火する条件を対象ディレクトリに csv ファイルが追加された場合のみに制限する仕組みも追加します。
それでは実装の詳細に入ります。今回変更を加えるのは audit-catalogs と apply-catalogs になりますが、ジョブの内容は同じものです。
GitHub Actions で各ステップを記述する
まずは seed の実行対象への変更を検知するために、対象ファイルの一覧を取得します。
- name: List dbt seed targets id: list-dbt-seed-target-csvs uses: tj-actions/changed-files@v38 with: files: | seeds/**/*.sql seeds/**/*.yml
ここでは seeds/ 配下にある sql ファイル、 yml ファイル一覧を取得します。
tj-actions/changed-files を用いると、指定したディレクトリ配下のファイルを変更の有無ごとに取得することができます。
変更状況は list-dbt-seed-target-csvs というオブジェクトに保持され、後段のジョブで呼び出すことができるようになります。
次に dbt seed の実行対象がある場合のみ、 dbt seed を実行します。
- name: apply dbt seed if: steps.list-dbt-seed-target-csvs.outputs.any_changed == 'true' run: | poetry run dbt --debug seed --target ${{ env.ENV_SHORT }}
if: steps.list-dbt-seed-target-csvs.outputs.any_changed == 'true' の部分では、先程 tj-actions/changed-files で取得したファイル変更状況を確認しており、1 つでも変更が入った場合に run の内容を実行します。
run では dbt seed をデバッグモードで ${{ env.ENV_SHORT }} で指定した dev, stg, prd 環境のいずれかで実行します。
最後に dbt test を行います。こちらも seeds ディレクトリに変更が入った場合のみ実行します。
- name: test dbt seed if: steps.list-dbt-seed-target-csvs.outputs.any_changed == 'true' run: | poetry run dbt test --target ${{ env.ENV_SHORT }} --select "config.materialized:seed"
dbt test 実行時の --select config.materialized:seed では seed マテリアルに対してのみテストを実行するよう指定をしています。これは config.materialized:table,config.materialized:snapshotなど他のマテリアルでも同様の指定が可能です。
docs.getdbt.com
最終的に audit-catalogs と apply-catalogs へ追加した内容をまとめると、以下になります。
- name: List dbt seed targets id: list-dbt-seed-target-csvs uses: tj-actions/changed-files@v38 with: files: | seeds/**/*.sql seeds/**/*.yml - name: apply dbt seed if: steps.list-dbt-seed-target-csvs.outputs.any_changed == 'true' run: | poetry run dbt --debug seed --target ${{ env.ENV_SHORT }} - name: test dbt seed if: steps.list-dbt-seed-target-csvs.outputs.any_changed == 'true' run: | poetry run dbt test --target ${{ env.ENV_SHORT }} --select "config.materialized:seed"
List dbt seed targetsでseeds/配下にある変更のあった sql ファイル、 yml ファイル一覧を取得します。apply dbt seedは seeds 配下に変更があった場合のみ、--target ${{ env.ENV_SHORT }}で渡した実行環境(dev, stg, prd)で dbt seed を実行します。test dbt seedで dbt seed で作成したテーブルに対してテストを実行します。
導入結果
今回の変更により、追加した csv ファイルに問題があった場合、PR 作成時に以下のような動作ができるようになりました。
Int 型を予定していたカラムにそうではない値
13365.00000が入っていた場合
Primary Key に重複があった場合
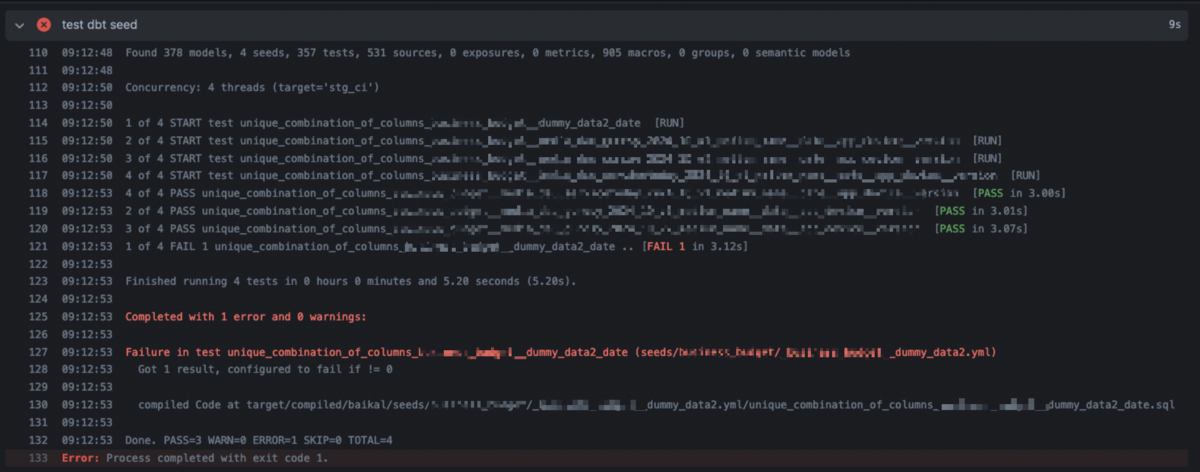
本格的な運用にはまだ載っていないのですが、今後この CI を使うことで PR マージ前に自動で失敗に気づける状態になると期待しています。
さいごに
今回は dbt seed と Github Actions を用いて csv ファイルからテーブル作成・データに対するテストを行う仕組みを紹介しました。 ヒューマンエラーが発生しやすい環境において、dbt でデータテストが行えることはとても頼もしく感じています。
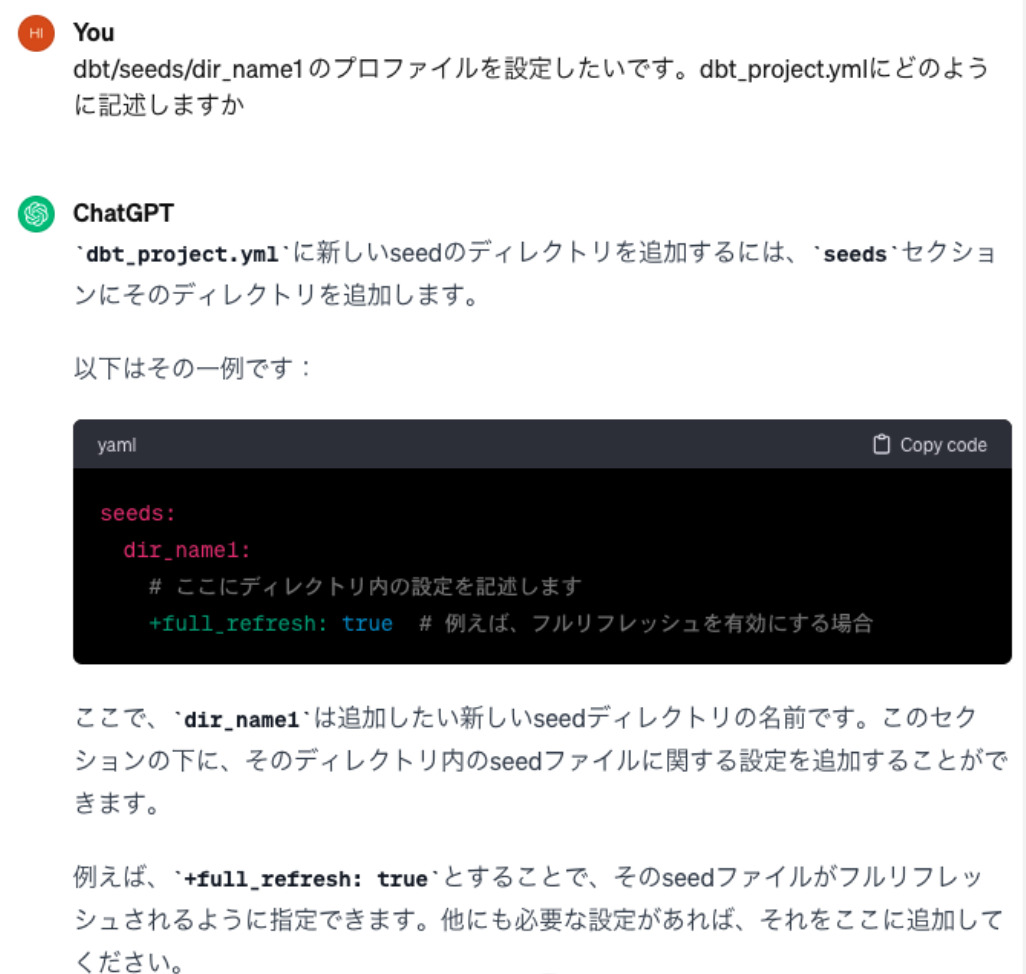
余談: ChatGPT にエラー解析と初心者解説を頼んだらかなり心理負荷が下がった
私は dbt を触り慣れているわけでもなく、それ以外のデータ基盤技術に対しても深い知識を持っていません。基本的には DRE チームの方々にサポートいただきながら今回の実装を進めることができたのですが、 ChatGPT にも大変助けられました。
エラー解析と基礎知識の理解は個人的に敷居が高く集中力を要するのですが、次のような質問を ChatGPT に投げたところ比較的楽に対処できました。(嘘に騙されることもありましたが)

参考文献
今回の実装にあたり、下記の文献を参考にさせていただきました。
*1:この場合スキーマを自動生成に頼るのではなく手書きになるトレードオフがある