はじめに
こんにちは、DR&MLOps*1 チームの楠です! こちらの記事は Gunosy Advent Calendar 2021 の 13 日目の記事です。
昨日の記事は大曽根さんの『Gunosyの施策運用におけるインスティチューショナルメモリ』でした。
本日は、データ分析の民主化を促進するためのデータレイク上での分析用データマートとしての Athena view の利用方法と、IaC のための Terraform による宣言的な Athena view の定義方法をご紹介します!
背景
Gunosy では、データレイク上で分析の民主化を達成することを目指した分析基盤作りを行なっています。 そのうちの大きなテーマの一つとして、「分析用データマートの拡充」があります。 いわゆる DWH 上でのスタースキーマに似た構成を目指したテーブル群を作成していくこと、それにより分析者側へ業務上のロジックを秘匿化することで、負担を軽減し分析を容易にすることが大きな指針です。 また、それらを GitHub 上のコードとして展開してくことにより、分析者の作業負担の低下や部署ごとの数値定義のずれの解消、CI/CD パイプラインの連携による開発体験の向上など、さまざまな恩恵が期待できます。
前提知識: Athena における view
まず初めに、view ではない一般的なデータテーブルについて述べ、その後に view について説明します。
一般的に Athena が参照するデータテーブルでは、その裏にデータ実体としてのファイルが存在しています。 そしてそのファイルの場所は Glue Data Catalog に登録する S3 上のパス(URL)情報となります*2。
たとえば、Gunosy のデータレイク『Baikal』*3では、主に Parquet*4 という列指向形式にしたテーブルデータを gzip で圧縮して S3 上に保管しています。ですから、そのファイル群が Athena 上の SQL で参照するテーブルのデータ実体であるといえます。そしてその保管情報を Glue Data Catalog に登録しておくことで、保管したデータファイルを Athena 側で SQL 上の「テーブル」として認識・参照できるようになります*5。
これに対して、view はその裏に 実体となる保管されたファイルデータを持たない のが特徴です。 テーブルからデータを取りだす SQL を書く利用者(分析者)からすると、一般的なテーブルと使い心地が変わりません。 ですが、テーブルデータをシリアライズした実体ファイルをソースとするのではなく、「view と対応する SQL を保管しておき、それを逐次実行することで、そのとき出てきた結果をソース」とします。他のクエリから参照された際に逐次 SQL を実行して出てきた出力を、保存していた実体ファイルを取り出してきたかのように振る舞います。このような形式から、view は「仮想テーブル」とも呼ばれます*6。
view には、次のような利点が考えられます。
Athena view の利点
利点1. SQL と view カタログ定義のみからなるので、データ転送ワークフローを組まなくてよい
レイクハウス上にテーブルを構築する場合は、データの変換・転送に Embulk や Athena を利用した、データを新鮮に保ったり時系列でアーカイブしていくためのバッチ処理が必要です。 そのため、ただデータを出力する SQL を書けばよいわけではなく、付随するいろいろな設定記述が必要でした。 そしてそれは分析者側のタスクではなく DR&MLOps 側への作業依頼であったため、分析者とテーブル作成に距離がありました。
ですが、view は後述する Terraform によるリソース記述と SQL ファイルさえあれば、テーブル定義をすることができ、データを見ることができます。 その点で、分析者でも記述することができる容易さを持っているといえます。
利点2. テーブルのスキーマを容易に変更できる
長期間に渡ってあるテーブルに時間情報を持ったデータを蓄えている場合、途中でスキーマが変更になると、テーブルとしての整合性を保つために保管開始から現在のデータまで新スキーマに対応させる(巻き戻して上書き更新する)、あるいは新たなテーブルとして切り分けて作成するなどの対応が必要になります。
それに対して view であれば、新スキーマに対応する出力の SQL を書いてしまえばただちに対応できるので、巻き戻して更新する作業は不要です。 そのかわり、view は参照するごとに分析者の関心のある期間すべてのデータを取り出してきて計算をすることになるので、データの読み込み量のコストが増加する場合があることに留意する必要があります。
利点3. よく利用する共通テーブル式をきちんとテーブルとして定義できるので、データマネジメントの観点で嬉しい
複雑な分析をする際には、ひとつの SQL ファイルの中で中間出力となる共通テーブル式(CTEs: Common Table Expressions)を用意して、それを参照して次の計算を進めることがよくあります。 しかし、この方式の怖い部分は、同じ数値になると期待していた CTE の中身(つまり With 句の計算ロジック)が分析ごとに異なっている可能性がある点です。 たとえば「売上」を CTE で計算しておいて最後に使いたい場合があるとして、その「売上」は定義によって大きく異なります。
- 消費税を含むのか?
- 年間契約は按分する?
- 返金はどうする?
そうすると、複数の分析者が記述したいくつかの分析の CTE における「売上」の数値が、きちんとすべて等しいかが怪しくなってきます。 このような事態を避けるためにも、分析者は共通化した売上の view を参照すべし、という運用の方がオレオレ定義や車輪の再発明を避けることができると考えます。 また、信頼して利用できるデータの抽象度が高まりデータの量が増えるため、分析作業の容易さも良い方向へ変化していくことが望めます。
テーブルと view の特性の違い
まとめると、一般的なテーブルと view で次のような特性比較ができます。
- テーブル
- 大量の業務データを効率よく取得できる
- スキーマの変更コストが大きい
- 分析の基礎となるような定型データの移行・変換先に適している
- view
- 上で述べてきた利点がある
- 参照するごとに SQL が走るので、頻繁に参照される基礎的なテーブルの定義には向かない
- 柔軟にスキーマを変更したい応用的な処理を Athena 上に落とし込むのに適している
これを元にして、Gunosy では次のように利用ケースを分けてどちらの機能も活用することにしました。
方針: 共通化できる分析作業は view として固めることで再利用できるようにして、分析者の負担を減らしていく
先述した view の特性から、データの持ち方を次の2つのコンテキストに分割することにしました。
- 業務で利用する RDB のスナップショットやログデータなど、カラムや用途が固まっていて信頼できる基礎的なデータであり、応用的なデータ加工の元となるテーブルに関しては従来通りのバッチ処理でデータを蓄え続ける
- 分析者が個別に必要とする分析用データマートは view として用意し、問い合わせに応じて都度 SQL を実行することで新鮮なデータを提供する
つまり、view によっていままでのワークフローに何かしらの入れ替えが発生するかというとそうではなく、いままで GitHub 上の IaC 基盤に載っていなかった分析者のクエリのうち、基礎的で共通化しうる部分を新たに view として共有資産にしようとしている試みである といえます。
これにより、データウェアハウスを持たなくても、データレイク上に分析に特化したデータ置き場を用意することが可能となります。 そしてこれは、新たなデータマネジメントアーキテクチャとして関心を集めている「データレイクハウス」的な設計思想に近いものではないかと考えています*7。 databricks.com
このような前提の元、具体的に行った施策はアドベントカレンダー 6 日目の記事を参照いただければと思います。 data.gunosy.io
Terraform での Athena view の記述方法
Gunosy では、Baikal データレイクのテーブルは Glue Data Catalog のカタログとして Terraform で記述し、GitHub で共有する IaC 管理をしています。 そのため、Athena view も既存の Terraform 管理基盤に載せることを考えました。 ただ、一般的な Athena 上のデータテーブル定義とは異なるお作法が必要でしたので、その部分の情報を共有します。
Terraform での Athena view の記述方法について、みんな悩んでいたようで stackoverflow に次のようなスレッドが立っていました。 stackoverflow.com
その中で、解決案を提示してくれている GitHub リポジトリを見つけたので共有します。 github.com
基本的にこのリポジトリの内容を利用しています。
使用例
このファイルから見て ./sql/ ディレクトリ配下に view の出力を定義する SQL ファイルがあるとしています。
このままコピーしても terraform apply はできませんので、日本語の部分を適当に書き換えてください*8。
resource "aws_glue_catalog_table" "Terraform リソース名を書きます" { database_name = "viewを置きたいデータベース名を書きます" name = "ビューの名前を書きます" description = "ビューの説明を書きます" table_type = "VIRTUAL_VIEW" parameters = { presto_view = "true" } storage_descriptor { ser_de_info { name = "-" serialization_library = "-" } dynamic "columns" { for_each = local.columns content { name = columns.value.name type = columns.value.hive_type comment = columns.value.comment } } } view_original_text = "/* Presto View: ${base64encode(local.presto_view)} */" } locals { columns = [ { name = "カラム1", hive_type = "date", presto_type = "date", comment = "カラム1の説明" }, { name = "カラム2", hive_type = "string", presto_type = "varchar", comment = "カラム2の説明" }, { name = "カラム3", hive_type = "bigint", presto_type = "bigint", comment = "カラム3の説明" }, { name = "カラム4", hive_type = "double", presto_type = "double", comment = "カラム4の説明" } ] presto_view = jsonencode({ originalSql = file("${path.module}/sql/SQLファイル名.sql"), catalog = "awsdatacatalog", schema = "viewを置きたいデータベース名を書きます", columns = [for c in local.columns : { name = c.name, type = c.presto_type }], }) }
一般的なデータカタログ定義とは異なるハマりどころとして、カラムのデータ型を hive_type と presto_type として2つ定義しておく必要があります。
これらの対応は参照元リポジトリにあるのでご確認ください。
あるあるエラー: SYNTAX_ERROR: line 1:2: View 'awsdatacatalog.hoge.fuga' is stale; it must be re-created
上記の方法で view を定義できた( terraform apply は実行できた)として、Athena コンソールで試しに view を選択して実行する段階になって次の添付画像のようなエラーがでる場合があります。
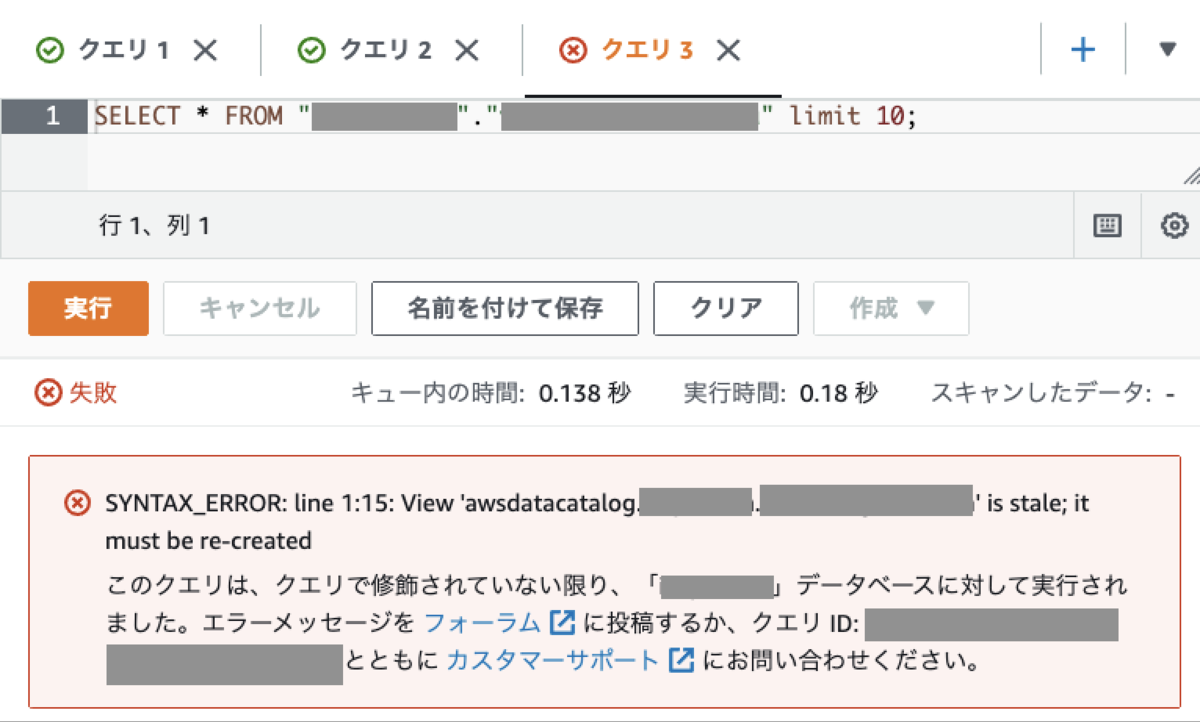
この場合、十中八九はカラム定義のどこかが間違っています。
hive_type、 presto_type の対応が取れていなかったり、SQL の出力結果の型と異なる場合です。
キャストし忘れている場合がよくあります*9。
まとめ
Terraform による Athena view の定義方法をお伝えしました。 また、view を活用したレイクハウス的なデータ基盤アーキテクチャに近付くための設計方針を提示しました。
今回はデータカタログに着目した内容でしたが、AWS のデータレイク周りは Lakeformation の権限設定やトランザクション系の新機能などまだまだ奥が深いテーマですので、引き続き改善を続けていきます。
おわりに
次回は、marice0819 さんの『AdKDD & KDD 2021 に参加しました』となる予定です。
アドベントカレンダーはまだまだ続きますので、引き続きよろしくお願いします!
*1:DR: Data Reliability の意です
*2:この構成は Presto ベースのクエリエンジンと、Hive メタストアベースのデータカタログからなる分散データ基盤設計を前提としています。詳しくはこのスライドなど: https://www.slideshare.net/AmazonWebServicesJapan/presto-amazon-athena
*3:Baikal についてはこちらの記事で詳しく述べています: Gunosy のデータ活用を支える統合データ基盤 Baikal の話 - Gunosy Tech Blog
*4:CSV や TSV といった行指向ファイル形式の親戚だと思ってください
*5:Athena は SQL を解釈して実行(データ問い合わせ)する際に Glue Data Calalog に問い合わせることで、 SQL 表現上の「テーブル名」と S3 上の「実体ファイル」との対応を得ることになります。これによりデータ取得を実現します。
*6:SQL を書いている人向けに述べると、「with 句でよく書く処理を別のテーブルとして切り離しておけば、from 句でいろんなところから参照できてハッピー」といえば伝わるかもしれません。ちなみに、view という言葉は Athena に特有のものではなく、データベース全般で同じ機能を持つ仮想テーブルに同じ単語が用いられています
*7:トランザクション対応やスキーマ運用などをサポートしているわけではないためすべての要件を満たしているとはいえませんが、より漸近するアプローチだと考えています
*8:また、local 変数はおなじモジュール内で衝突するので複数の view を定義する際には ${view_name}columns や ${view_name}presto_view のように view 定義ごとに一意な名前を取るようにしておくことをおすすめします
*9:timestamp と date の齟齬などがよくあります