本記事は、Gunosy Advent Calendar 2020 19日目の記事です。
昨日はサンドバーグさんの Amazon AthenaのPartition Projectionを使ったALB Access Logの実例 (w/ terraform & glue catalog) - Gunosy Tech Blog でした。
こんにちは、GTL(Gunosy Tech Lab) 所属のクボタです。
社内では主にニュースパスというアプリの分析などを行なっています。 本記事ではA/Bテストの実施が難しい場面でチームでも利用している因果推論による効果検証について簡単に紹介させていただきます。
はじめに
Gunosyではアプリ内でのロジックやUIの変更、キャンペーンなどの施策においてデータに基づく効果検証をしています。 効果検証では分析対象の施策起因による変化である因果効果のみを求めたいですが、方法を誤るとバイアスが混入して結果を歪めることがあります。 例えば、効果検証の方法として
- 施策開始前後の同一ユーザー群での比較
- 施策の影響有りのユーザーと無しのユーザー2群に分けての比較
などの方法が直感的に考えられます。 しかし、1では指標が時期に依存してる場合や施策開始前後での他の状況の変化によるバイアスが発生してしまいます。 2では時期によるバイアスは防げそうですが、分け方によってはユーザー群の性質の違いによるセレクションバイアスが新たに発生してしまいます。 理想的には同じユーザー群で施策を実施する場合としない場合で比較したいですが物理的に不可能です。 例えば、薬の効果検証をしたい際に一人の人間を同時に処方有りと無しの両方の群に属することはできません。 これを因果推論の根本問題と言いバイアスを回避して因果効果を得るために工夫が必要なことが分かります。
A/Bテスト
効果検証の代表的な方法としてユーザーをアプリの変更有り/変更無しでランダムに振り分けて同時期で数値の変化を比較するRCT(Randomized Controlled Trial)があります。 RCTはA/Bテストとも呼ばれ、様々な企業で利用されておりGunosyでも常に並行して幾つかのテストを行なっています。 A/Bテストならば同時期の比較のため時期の違いによるバイアスは無く、ランダムに群を生成しているためユーザー群の性質の違いによるバイアスも無くなると期待されます。
しかし、施策によってはランダムにユーザーを振り分けることが難しいなどの理由でA/Bテストによる検証が行えないことがあります。 例えば、アプリの分析でも度々ありますがユーザーが参加するかを選択できるキャンペーンの場合は参加有無の2群をランダムに分けることが出来ず、参加する群の方にヘビーユーザーが偏りやすくなるため参加有無による効果を測ることが難しくなります。
因果推論における介入とバイアス
バイアスを調整する具体的な方法に移る前に因果推論の言葉で効果とバイアスの問題を考えていきます。 因果推論では数値に変化をもたらすアプリ内でのロジックやUIの変更、キャンペーンなどの施策を『介入』、介入起因の変化を『因果効果』と言います。 以下のように変数を定義します。
- 各ユーザー
の介入の有無を
- 各ユーザー
の値
指標 は売上やアプリ訪問数、クリック数などで
は効果を検証したいキャンペーンの参加有無などを表します。
因果効果は介入がある場合と無い場合の期待値の差
]
]
で定義出来ますがこれは上記の因果推論の根本問題のとこで述べたように観測することが出来ません。
そこで観測できる2群間の条件付き期待値の差を考えると
]
]
と表せます。これを式変形していくと
]
]
]
となります。
] は
となるユーザー群の因果効果で求めたいものですが、
]
]は介入がない場合の各群の期待値の差で施策を行わなかった時の各群の指標の変化の期待値なのでセレクションバイアスに対応しています。A/Bテストでバイアスなく効果検証できるのは群の所属がランダムで
]
] となるためです。
共変量によるバイアス調整
これまでの議論からA/Bテストが出来ない場合、単純な2群間の差で現れてしまうバイアスを調整する必要があることが分かりました。
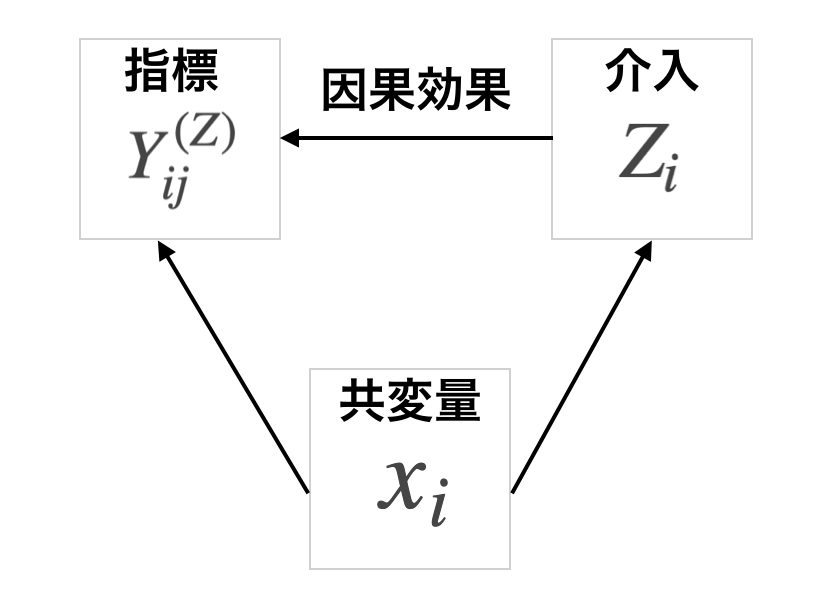
そのためにここで共変量という変数を新たに導入します。
共変量は以下の図のように介入の有無 と変化を見たい指標
両方に依存する量です。
例えば年齢、性別、アプリ内でのアクティビティなどが共変量になりえます。
キャンペーンの例で言えば、過去のアプリのアクティビティが高い方がアプリのヘビーユーザーでありキャンペーンの参加率が高く、因果効果が見たい売上やアプリ訪問数も元々高いことが予想されます。
この共変量を群間で調整することでバイアスを抑える方法の一部を以下で少し紹介いたします。
共変量マッチング
共変量マッチングは共変量によるバイアス調整の方法として非常にシンプルです。
の群の共変量と
の群の共変量の近いユーザーをマッチングして差の平均を取れば、
似たユーザー同士の比較の平均のためセレクションバイアスを抑えて因果効果を得ることが出来ると考えます。
共変量マッチングは非常に分かりやすいですが、共変量の次元が大きくなるとマッチングさせる量が多くなることやマッチング自体が難しくなるため注意が必要です。
傾向スコアマッチング
共変量マッチングの問題点を和らげる方法の一つとして傾向スコアマッチングが有ります。
傾向スコアはユーザー の共変量ベクトルを
とすると
で定義され
共変量
のユーザー
に介入がある確率になります。傾向スコアは共変量を特徴量としてロジスティック回帰などで求めることが多く、モデルの評価はAUCが0.7~0.8以上あるといいと言われていますが諸説あり問題ごとに共変量のバランスを見るなどした方が良さそうです。傾向スコアは共変量を1次元に縮約した量のため共変量マッチングでの次元の問題を和らげることが出来ます。マッチングの評価は各共変量の平均の差を標準偏差で割ったものが0.1より小さければ良さそうと言われています。傾向スコアマッチングの問題点としては、データが多い際にマッチングの計算で非常に時間がかかるためIPW推定量など他の方法も考慮に入れると良さそうです。
おわりに
データ分析による意思決定においてA/Bテストが使えない局面も多くありその際に発生するバイアスの問題や利用される因果推論的な方法の一部を簡単に紹介させていただきました。因果推論による効果検証は奥が深い領域でもありながら現場の分析で試せる機会も多く、勉強しやすい本(調査観察データの統計科学や効果検証入門など)も出ているため今後も様々なケースに対応できるように今後も知識を拡げていきたいと考えています。