はじめに
こんにちは、Gunosy Tech Lab - Media MLの suchida です。
気温の低下とともに起床時間が遅くなってる今日この頃です。
早く春にならないかなぁ(笑)。
さて本記事では、知識辞書構築の自動化について紹介します。
特に記事配信システムの一部で利用している人名辞書について取り上げます。
人名辞書とは
人名辞書は、社内で独自に作成している知識辞書です。 具体的には、以下のように人名やグループに対してカテゴリの紐付けを定義している辞書です。 ちなみに、直近では約19万単語が収録されています。
さだまさし: エンタメ, ヨハン・クライフ: スポーツ, ジョセフ・スミス・ジュニア: エンタメ, ボリス・スパスキー: スポーツ, ルーホッラー・ホメイニー: 国際,
この辞書は、Wikipediaのデータをベースに構築しています。 具体的には、Wikipediaにおけるページの記事タイトルとそのページに紐づくカテゴリ情報を用いて人物系ページを特定し、本文のキーワードを抽出してカテゴリを付与しています。
利用用途
人名辞書は、記事のカテゴリ分類やタグ付けシステムなどで利用しています。 人名に対する補助情報としての利用や、人名の正規化にも利用が可能です。
辞書構築を自動化しよう
なぜ?
以前は辞書構築を手動でスクリプトを実行して作成しており、一度作成した辞書を使い回すという運用になっていました。 しかし、これでは新しい人物*1が登場した場合に対応できないという問題があります。 そこで、未知の人物に対応するため定期的に辞書を更新できるように、システムを自動化するに至りました。
構成
最終的な構成は以下のようになっています。
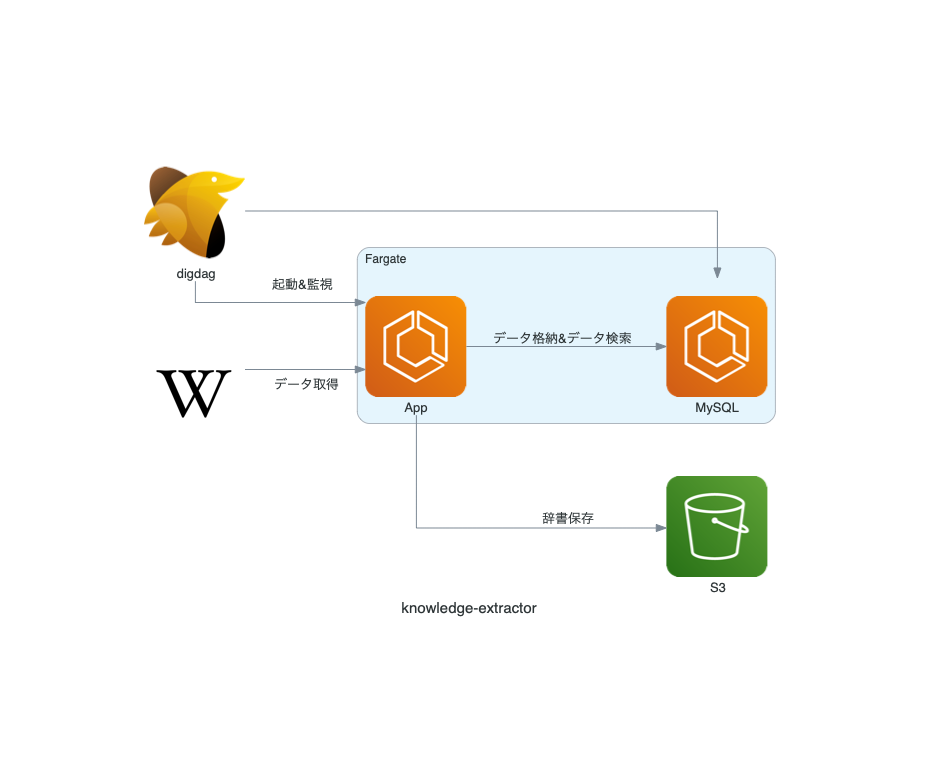
辞書構築システムの内部処理
まずはじめに、辞書構築システムが内部でやっていることを紹介します。
辞書構築システムでは、MySQLコンテナとAppコンテナの2つを用いて処理を行っています。
docker-compose.ymlはこんな感じです(クリックして展開)
version: "2.0" services: db: container_name: mysql-container build: context: ./ dockerfile: docker/Dockerfile.mysql ports: - "3306:3306" tty: true networks: - network app: container_name: app-container build: context: ./ dockerfile: docker/Dockerfile working_dir: /src environment: - MYSQL_HOST=mysql-container volumes: - .:/src tty: true depends_on: - db networks: - network networks: network: driver: bridge
まずは、必要なデータをAppコンテナに取得します。 Wikipediaのデータは、以下の3つを利用しています。(参考)
jawiki-latest-pages-articles.xml.bz2 - 全ページの記事本文を含むXML jawiki-latest-page.sql.gz - ページ情報(page_idやタイトル等) jawiki-latest-categorylinks.sql.gz - 各記事がリンクしているカテゴリ情報を保存しているテーブル
各データは、取得したのちMySQLコンテナへ格納していきます。 本文データについては、wikiextractorを用いてデータ整形を行ったのち、必要データのみをPythonで抽出し同様にMySQLへ格納しています。 DBに格納することで、検索性の向上や省メモリにもつながります。 代わりに処理速度の低下は許容します。
Tipsとして、MySQLへデータを解凍する際に、データ転送量が大きいことに起因したエラーに遭遇することがありました。
その場合は、max_allowed_packetを設定し上限を引き上げることで、エラーを回避することができました。
データの格納が終了したら、Pythonを利用して辞書構築を行います。 おおまかな手順としては、以下のようになります。
- 人物系ページの抽出
- 本文の取得
- キーワードマッチングによりカテゴリ付与
- 辞書の保存
人物系ページの抽出では以下のようなクエリを利用しており、人物っぽいカテゴリを持つページを人物系ページとして抽出します。
合わせて本文冒頭を取得しており、例えば、{'春風亭与いち': '春風亭 与いち(しゅんぷうてい よいち、1998年4月5日 - )は、宮城県出身の落語家'}のようなデータが得られます。
WITH target_pages AS ( SELECT page_id , page_title FROM categorylinks JOIN page ON cl_from = page_id WHERE cl_to LIKE '%人物' OR cl_to LIKE '%アーティスト' OR cl_to LIKE '%アイドル%' OR '%政治家' OR '%議員' OR '%大臣' OR '%選手' -- REGEXP_LIKE使いたかった... ) SELECT DISTINCT page_title , SUBSTRING_INDEX(page_articles.text, '。', 1) AS article_head FROM target_pages JOIN page_articles ON page_articles.id = target_pages.page_id
あとは、事前に用意しておいたカテゴリに紐づくキーワード(例えば、{落語家:エンタメ})と本文を照合してラベリングを行う流れです。
AWS上で運用する
ローカルでの動作確認が完了したら、実際にAWS上で運用できるようにシステム構築していきます。
今回はリソースの都合もあり、ECS on Fargate上で辞書が構築できるようにしました。 システムの動作手順としては、以下のようになります。
- digdag workflowからジョブを実行(定期的)
- MySQLコンテナとAppコンテナをECS上に構築*2
- Wikipediaデータの取得と格納
- Appコンテナで辞書構築を行い、ファイルをS3にアップロード
タスク定義は以下のようになっています。(一部省略)
{ "containerDefinitions": [ { "portMappings": [ { "hostPort": 3306, "protocol": "tcp", "containerPort": 3306 } ], "image": "hogehoge/mysql", "essential": true, "name": "MySQL" }, { "command": [ "app" ], "image": "hogehoge/app", "dependsOn": [ { "containerName": "mysql", "condition": "START" } ], "essential": true, "name": "App" } ], "taskRoleArn": "fuga", "executionRoleArn": "fugafuga", "requiresCompatibilities": [ "FARGATE" ], "networkMode": "awsvpc", "memory": "4096", "cpu": "2048", "ephemeralStorage": { "sizeInGiB": 200 }}
コンテナはMySQLとAppの2つです。 以下に、システム構築にあたって得られたTipsを紹介します。
Tips
コンテナ間通信
Fargateで簡単にコンテナ間通信を行うためには、以下の2つが必要です。*3
- 同一タスク定義に記述すること
- MySQLコンテナ側でのポート開放
これにより、Appコンテナから127.0.0.1:3306にアクセスすることでMySQLコンテナに接続可能になります。
コンテナ間依存関係
dependsOnの設定により、コンテナ間依存関係を記述することができます。
今回だとMySQLコンテナの起動を少し待ってから、App側の処理が始まります。
ただ、Appコンテナ起動後の最初の処理はWikiデータのダウンロードなので、特に考慮しなくても良さそうです。
また、essentialの設定により、片方のコンテナがストップしたら自動的にもう一方のコンテナも終了するようになります。何もしないとMySQLコンテナは起動しっぱなしになるので、App側の処理が終了したら自動的に終了するようにします。
コンテナストレージ拡張
ephemeralStorageの設定により、ストレージ拡張が可能です。
Amazon ECS on AWS Fargate で最大 200 GiB のエフェメラルストレージを設定できるようになりました | Amazon Web Services ブログ
ephemeralStorageを設定する前では、MySQLへのデータ投入中にCPUがほぼ動かなくなってしまうエラーが起きていました。
ログを調査していると、ストレージ書き込み量が大きそうだと分かりましたので、コンテナで不要になったデータはどんどん削除するようにコード修正しました。
これにより多少の改善がみられたので、やはりストレージが影響してそうという結論に至りました。
ECS on Fargateのデフォルトストレージは20GBなので、ephemeralStorageを設定しストレージ拡張してみると、エラーにならずに辞書構築を完了することができました。*4
ただ残念ながらephemeralStorageを設定しても、処理途中でCPU使用率が減少することは回避できませんでした。
現状は処理時間:約5時間と現実的な時間で終了しているのでそのままにしていますが、今後の改善に期待です。
おわりに
本記事では、知識辞書構築の自動化について紹介しました。
ローカル環境とクラウド環境の違いにかなり苦戦しましたが、一応動く形になってよかったです。
ephemeralStorageについては、開発時期の3ヶ月前にリリースされたものなので、これがなかったら詰んでたかもしれません(笑)。