
こんにちは、研究開発チームの飯塚です。11/1~11/5にオンラインで行われた、CIKM2021に発表参加しました。CIKMとはACM International Conference on Information and Knowledge Managementの略称で、機械学習やWebマイニング、情報検索/推薦といったトピックを扱う国際会議の1つです。今年のCIKMも、新型コロナウィルス感染症対策の観点からオンラインで開催されました。Gunosy社として、このCIKMに参加するのは初めてでした。本記事では、今回投稿した論文の経緯や概要、ニュースに関する他研究者の発表の一部をご紹介します。
投稿論文
近年オンラインメディアでは、タイトルや画像などを誇張したクリックベイト記事、ユーザーをミスリードするような釣り記事の問題が指摘されています。また、推薦システム側の問題としては、パーソナライゼーションアルゴリズムを通して、一度クリックベイト記事をクリックすると徐々にクリックベイト記事ばかり推薦されてしまうといったフィルターバブル問題があります。このような状況を助長するようなメディアには、広告主が広告の出稿を控えるといったビジネス上のリスクが考えられます。
そこで、Gunosy社では現在、長期的なプロダクト価値の向上を目指して、記事の品質に着目した施策を講じています*1。具体的な施策の1つとして、ユーザーに推薦する記事の上位に品質の担保された記事を優先的に配置するという施策があります。今回CIKMに投稿した論文は、この記事品質の施策を講じたときのユーザー行動に着目し、ニュース記事の品質が広告の消費にどのような影響を与えるかを分析した論文*2になります。タイトルは、 The Effect of News Article Quality on Ad Consumption です。
今回の論文の知見は、品質の高い記事をユーザーに優先的に配信することが、ユーザーの広告消費を促進した点です。
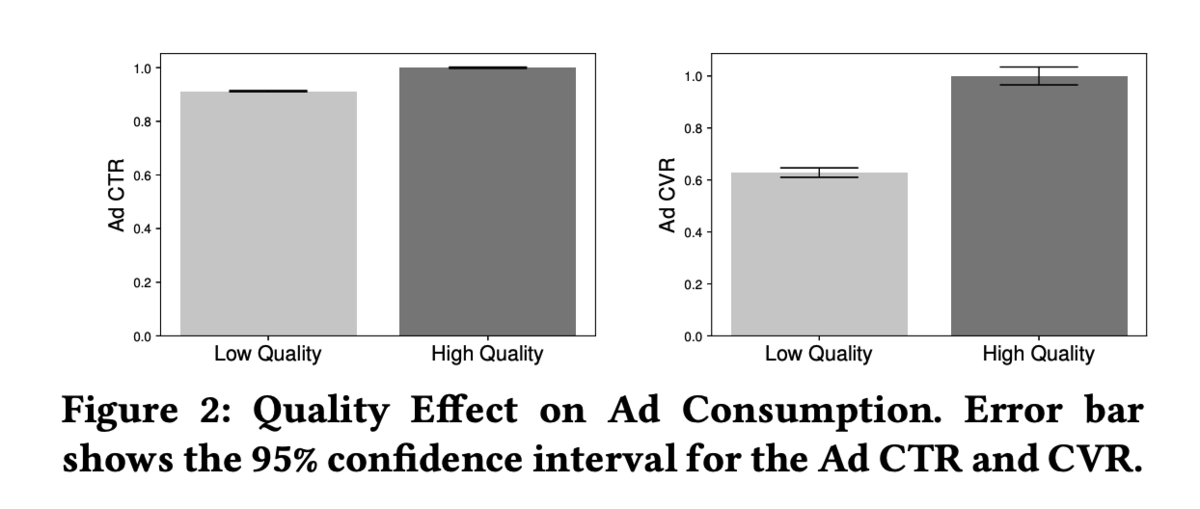
この図は、広告の上に記事品質の高い記事があるか低い記事があるかに応じて、広告効果を測定した結果を表しています*3。
今まで、品質の高い記事を提示することは、基本的に記事のクリック率などが低下し、サービスへの導入メリットが薄いと考えられていました。そのため、記事品質を担保するような仕組みを推薦システムに組むことができていませんでした。しかし、広告の消費においてはポジティブな側面がある、ということを初めて明らかにし、その貢献が学会にも認められ short-paper として受理されました。既存の研究では、記事と広告の消費は独立の関係にあるという仮定のもと、記事と広告をユーザーに提示するモデルが開発されていました。今回の知見を利用して、記事に関する品質と広告消費の影響をモデルに組み込むことで、より正確な最適化が行えるのではないかと期待されます。
ポスターセッション

この画像は、ポスターセッションの開始を待機しているときに撮影したスクリーンショットです。ポスターセッションでは他の国際会議同様に、Gatherが用いられました。今回のオンラインポスターセッションも発表者以外いない部屋に入って会話をするときの心理的ハードルの高さがありました。コロナが収束して対面でわいわい議論できる日が早く来ることが望まれます。
ニュースに関する研究セッション
CIKMの中で、ニュースに関するセッションはチュートリアルと一般発表のそれぞれに1セッションがありました。
チュートリアルには、Fake News, Disinformation, Propaganda, and Media Bias *4と題したセッションがありました。このチュートリアルは、フェイクニュースが実社会にどのような実害をもたらしているかといった例から始まり、Pre-trainモデルを用いたフェイクニュース検知まで、近年のオンラインニュースメディアに関する問題や現状の対策が幅広く説明されていました。資料はこちらに公開されています。
cikm21_fake_news_tutorial.pdf - Google ドライブ (少し重いため注意)
一般発表はZoom上で行われており、ニュースに関するセッションとしてはFake news, rumours and fact checking (harmful online content) *5と題したセッションがありました。このセッションはリアルタイムで参加している論文投稿者がその場で口頭発表を行うスタイルでした。発表の中で気になった論文が、WikiCheck: An end-to-end open source Automatic Fact-Checking API based on Wikipedia *6 です。この論文は、Wikipediaの記事に基づいて、主張のFact-Checkingを行うAPIを開発したというものです。もちろんAPIを開発した、という以外にも技術的な貢献が論文には含まれていますが、このような実用的な側面を押し出した論文に個人的に興味を惹かれました。このAPIのエンドポイントは外部に公開されており、自由に呼び出すことができます。
例えば、"Donald Trump is a baseball player."という主張のFact-Checkを下記のようにAPIを呼び出し行ってみます。
curl -X GET "https://nli.wmflabs.org/fact_checking_model/?claim=Donald%20Trump%20is%20a%20baseball%20player." -H "accept: application/json"
すると、下記のようなレスポンスが得られます。
{ "results": [ { "claim": "Donald Trump is a baseball player.", "text": "Donald John Trump (born June 14, 1946) is an American politician, media personality, and businessman who served as the 45th president of the United States from 2017 to 2021", "article": "Donald_Trump", "label": "REFUTES", "contradiction_prob": 0.8146684169769287, "entailment_prob": 0, "neutral_prob": 0.1853315532207489 }, ... ]
この出力例のlabelはREFUTESなので、主張に対立する記事(Donald_Trump)があることを教えてくれます。
次に、"Donald Trump is a professional businessman."という主張を入力すると下記の出力が得られます。
{ "results": [ { "claim": "Donald Trump is a professional businessman.", "text": "(born December 31, 1977) is an American political activist, businessman, author, and former television presenter", "article": "Donald_Trump_Jr.", "label": "SUPPORTS", "contradiction_prob": 0.036707211285829544, "entailment_prob": 0.9632927775382996, "neutral_prob": 0 }, ... ]
この出力例のlabelはSUPPORTSなので、主張を支持する記事(Donald_Trump_Jr)があることを教えてくれました。興味のある方はぜひ実際にエンドポイントを叩いてみてください。
おわりに
今回投稿した論文は、社内の取り組みの中で生まれた知見を研究開発チームが再度検証し、学術コミュニティに還元した形になります。研究開発チームとして、新しいアルゴリズムやフレームワークを開発するだけでなく、このように社内の取り組みの検証役のような新しい形で連携できたのは良かったと思います。研究サポートを持続的に行ってくださっている社内の関係者をはじめ、筑波大学の加藤研究室の皆様(特に加藤先生)に感謝いたします。Gunosy社は、今後とも研究ならびに開発の知見を深めつつ、継続的に外部のコミュニティとの接続を行っていきたいと考えています。 今後ともどうぞよろしくお願いいたします。