こんにちは、Gunosy Tech Lab DR&MLOps チームの楠です。
この記事は Gunosy Advent Calendar 2022 の 11 日目の記事です。 昨日の記事は UT@mocyuto さんの『RailsのフロントをReactへリファクタしたとき、スキーマをOpenAPIベースの自動生成にした話』でした。
この記事では、ELT パイプラインにおける Transformation ツールである dbt の snapshot という機能について紹介した後、snapshot の手法を一般化したディメンションモデリングにおける概念である Slowly Changing Dimension を包括的に紹介します。
- はじめに
- dbt とは?
- dbt snapshot とは?
- この後は?
- SCD Type 0~3: 基礎を学ぶ
- SCD Type 4 ~ 7: 発展的な設計を学ぶ
- まとめ
- おわりに
はじめに
近年、データエンジニアリングに大きな関心が集まっています。データ基盤システムに関するソフトウェア製品が数多くリリースされていますし、エンジニアの主軸コミュニティである勉強会においても、Forkwell 様が Data Engineering Study をホストされており、たくさんの方が参加しています。
その中でも、特に dbt (data build tool) を取り巻く一連の環境は特筆すべきものであるように感じています。弊社でも、社内データ基盤をよりよくするために dbt の導入を予定しております。
本稿では、dbt の機能の中でも少し珍しい機能である dbt snapshot について取り上げます。もしかしたら、dbt を利用されている人の中にも snapshot は使ったことがないという方もおられるかもしれません。
その理由として、一見した時の難解さがあるように感じられます。snapshot の公式ドキュメントの説明ページを開くと、すぐに type-2 Slowly Changing Dimensions なるものの紹介がされています。こういった場合、「なんとなく難しそうだし、後で調べるか...」と思い、そのままになりがちです。
ですので、この記事は Slowly Changing Dimension に対するある程度 self-contained なコンテンツを提供しています。この記事を読めば、最低限 Slowly Changing Dimension の Type 0~7 が何を意味しているのかわかるようになるというのが本稿の意図したところとなります。
みなさまの理解のお役に立てば幸いです。
dbt とは?
データウェアハウス内部で既存データテーブルを加工して、所望のデータを持ったテーブルを新たに作る作業を Transform と呼びます。このためのデータ定義 + SQL 実行を、YAML による宣言的な設定記述と Jinja テンプレートエンジンによる柔軟な対応実装で達成する点がプロダクトとしての魅力となります。
代表的な機能は、次のふたつです:
dbt run- dbt プロジェクトで宣言した状態を達成するためにワークフローを実行する
dbt docs generate/serve- dbt プロジェクトのドキュメントを生成・提供する
基本的には上 2 つでユースケースを達成できますが、特殊なケースでは dbt snapshot が必要となります。まずは具体例を用いて、どのような場面で dbt snapshot が必要になるのかを説明します。
dbt についての参考資料
dbt snapshot とは?
どんなときに使える?
具体例で説明します。
社内のとあるシステムには、取引先の情報を保存したテーブルがあります。
データ基盤チームの管理するデータウェアハウス(以降 DWH と記述します)には、このテーブルの最新の状態を定期的に取り込んでいます。以後、このように DWH に取り込む対象のテーブルを「ソーステーブル」と呼称します。
ソーステーブルの DWH 側でのスキーマは次の通りです:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 |
ここでの 取引先 Key は DWH 側でレコードに用意するキー(サロゲートキー)とします。
もし取引先の住所が移転した場合、このレコードは上書きされます(港区 → 渋谷区):
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都渋谷区 |
DWH の値も、次のデータ取り込みタイミングで同様に上書きされてしまい、履歴は残りません。
これは DWH のメインユーザであるデータアナリストにとって痛手となります。DWH が取引先住所の時間的な変化を持ち合わせていないためです。このままでは、取引先住所は横軸に時間を使った可視化に採用する分析軸にできないなどの制約が発生してしまいます。
dbt snapshot でこの問題をどのように解決するかを次に述べます。
dbt snapshot が定義されると、対象のスキーマに内部的なカラム dbt_valid_from 、 dbt_valid_to のふたつを追加したテーブルを DWH で定義することになります。
最初の状態では、次のようになります:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 | dbt_valid_from | dbt_valid_to |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都渋谷区 | 2022-12-01 | null |
次に、 2022-12-11 に取引先の住所が港区から渋谷区に変更されたとします。 dbt snapshot はその変化を検知し、対応します。このとき、住所を上書きするのではなく、新たな住所のレコードを追加します:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 | dbt_valid_from | dbt_valid_to |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-01 | 2022-12-11 |
| 124 | ABC | ぐの不動産 | 東京都渋谷区 | 2022-12-11 | null |
古い港区の住所のレコードは dbt_valid_to が null から 2022-12-11 となったため、この日以降は有効なレコードでなく、より新しい状態を持ったレコードが別に存在していることを表現しています。
新しく発行された渋谷区の住所のレコードは dbt_valid_from が 2022-12-11 であるため、この日から有効なレコードであることを示しています。そして、現時点では dbt_valid_to が null のため、最新の有効レコードであることも示しています。
これにより、システム側に変更を加えることなく、DWH 側で状態変化の履歴を追いかけられるようになりました。これが dbt snapshot の機能です。
dbt snapshot のまとめ
データの状態変化が起こりうるようなソーステーブルに対して、状態を追いかけられるスナップショットテーブルを構築します。状態とその有効期間の履歴情報を新しくカラムに持ち、ソーステーブルのレコードの状態が変化した場合は、変化後の値を持ったレコードを新規発行することで対応します。
dbt snapshot についての参考資料
この後は?
dbt プロジェクトで上記の課題に対してプリミティブな機能でできることは dbt snapshot だけです。なので、dbt ユーザーとして知っておくとよいことは基本的に上記の仕様ですべてです。
ですが、対応策は dbt snapshot しかないのでしょうか?
実は一般的な対応のモデルがすでに知られており、こういったテーブルの状態変化の性質を Slowly Changing Dimension(以降 SCD と記述します)と呼びます。そして、この SCD に対処するような DWH のデータ管理方法として、「Type 0」から「Type 7」までの付番された管理方法が存在します。 dbt snapshot は Type 2 の手法であることが、公式ドキュメントからもわかります。
Snapshots implement type-2 Slowly Changing Dimensions over mutable source tables. Snapshots | dbt Developer Hub
本稿の後半では、Type 0 から Type 7 までを包括的に説明します。これにより、データエンジニアとしての DWH への深い理解の涵養を目指します。
「8 個も紹介するのか!!」と思われるかもしれませんが、思ったよりも難解な内容はありません。Type 0 ~ 3 は特にすぐに理解できます。 dbt snapshot の説明と同様に、「取引先」テーブルの具体例を交えながら説明します。この機会にぜひご覧ください。
SCD Type 0~3: 基礎を学ぶ
SCD Type 0: オリジナルのまま、何もしない
Type 0 の実装
一番最初に DWH に取り込んだレコードの値をそのまま維持し続け、変化に対して特別な対応をしません。ソーステーブル側でレコードの状態が変わっても、気にしません。先述の例でいえば、最初の港区の住所を持ち続けることに相当します:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 |
もちろん、新たな取引先レコードが追加されていればそれは DWH 側でも新規レコードとして追加します。ですが、そのときに追加したレコードの状態に変更を加えるようなことは、以後しません。
Type 0 であるということは、そのカラムはソーステーブル側で変化することがないと仮定していることを表現できます。このため、Type 0 を能動的に採用するというよりは、「SCD としての特別な対応の必要がないカラムである」ことを Type 0 と表現している、と私は解釈しています。
SCD Type 1: 変化したら、上書きする
Type 1 の実装
最初のレコードは次のようになっているとします:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 |
取引先の住所が移転した場合、このレコードは上書きされます(港区 → 渋谷区):
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都渋谷区 |
DWH も、これに対応してレコードを上書きします。つまり、状態をそっくりそのまま追従させます。
Type 1 の特徴
利点は、対象テーブルに追従するだけなのでメンテナンスが容易なことです。
欠点は、DWH に履歴が残らないことです。分析者のユースケースによっては、使えないデータをただただ抱えていることになってしまいます。また、サマリーデータに用いられている場合は、状態の変更に合わせて再度集計を実施する必要があります。
SCD Type 2: 新規レコードの追加で変化に対応する
Type 2 の実装方法はいくつかあります。本稿では 3 つを紹介します。
Type 2-1: バージョンで管理
バージョン番号カラムを持つテーブルで管理します:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 | version |
|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 1 |
| 124 | ABC | ぐの不動産 | 東京都渋谷区 | 2 |
レコードに変更があった場合は、新規レコードを追加しバージョンをインクリメントしていきます。
Type 2-2: 有効期限で管理
有効期限の開始と終了を表す start_date , end_date のふたつのカラムを持つテーブルで管理します:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 | start_date | end_date |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-01 | 2022-12-11 |
| 124 | ABC | ぐの不動産 | 東京都渋谷区 | 2022-12-11 | null |
レコードに変更があった場合は、新規レコードを追加し start_date には現在時刻、 end_date には null のような特殊な日付を入れます。既存レコードは新規レコードに取って代わられるので、このタイミングで end_date を現在時刻に上書きします。
( null の他にも、 9999-12-31 のような特殊な日付をシステムで決定しておくなどのやり方があります。クエリ側で null への対応が必要なくなるため、利用者にやさしい作りとなります。)
dbt snapshot で説明した手法はこの Type 2-2 の実装といえます。
Type 2-3: 開始日とフラグで管理
有効期限の開始を表す effective_date 、現在有効かどうかの current_flag のふたつのカラムを持つテーブルで管理します:
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 | effective_date | current_flag |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-01 | false |
| 124 | ABC | ぐの不動産 | 東京都渋谷区 | 2022-12-11 | true |
レコードに変更があった場合は、新規レコードを追加し effective_date には現在時刻、 current_flag には true を入れます。既存レコードは新規レコードに取って代わられるので、このタイミングで current_flag を false に上書きします。
フラグのフィルタリングで現在有効な値を取り出せるため、使い勝手がよいです。
Type 2 の特徴
同じ取引先に対して Key まで更新されるため、サロゲートキー( 取引先 Key )はある時間における状態への対応となり、かならずしも最新の状態を参照しません。そのため、状態に依存した計算が DWH 側にある場合は Key で参照すれば副作用がないという利点があります。 取引先 Key = 123 とすれば、必ず港区に住所があった時代のぐの不動産のレコードを得ることができます。
その逆に、取引先に対してレコードが一意でないため特別な対応が必要な部分が欠点となります。 取引先コード = ABC とするだけではレコードを得ることができません。また、変更が多いとレコードが大量に発行されてしまう欠点があります。一部分だけの変更につられて、意図しないほどテーブルが膨らむ可能性があります。
Type 2 の注意点
ソーステーブル側で、対象としているカラム(例における 取引先住所 )に遡及的な変更があると、DWH 側でそのテーブルを参照して算出していた後続データにもすべて更新をかける必要があります。
また、ソーステーブルに新たに別の時間軸で変化するカラム(例えば 営業担当者名 など)が付与される場合にも、DWH 側で完全な複製をする場合には追加の遡及対応が必要となります。これは一般に高コストな処理となります。
このように、ソーステーブル側の頻繁な変更が予想される場合に Type 2 を選択するのは、よい選択ではないと考えられます。
SCD Type 3: カラムの追加で変化に対応する
Type 2 とはまったく異なる方法を取ります。テーブルにカラムを追加して、直近の変更を追跡します。
Type 3 の実装
取引先住所の変化を追いたいため、取引先住所を original_ プレフィックスを付けたカラムと、 current_ プレフィックスを付けたもののふたつのカラムに分割します:
| 取引先 Key | 取引先コード | 取引先名 | original_取引先住所 | effective_date | current_取引先住所 |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-01 | 東京都港区 |
original_取引先住所 には、最初にデータを取り込んだときの状態を保持しておきます。
ソーステーブルに変更があった場合は、 effective_date を更新し、 current_取引先住所 を最新の状態に上書きします。 original_取引先住所 は以前の状態である 東京都港区 のままにしておきます:
| 取引先 Key | 取引先コード | 取引先名 | original_取引先住所 | effective_date | current_取引先住所 |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-11 | 東京都渋谷区 |
このようにして、前回の変更の状態を 1 レコードに含むことが一応は可能となります。
ですが、取引先が新たな 2 回目の住所変更を行なった場合には、途中で渋谷区の住所を持っていたことまで追跡できません。次のようになってしまうためです( 2022-12-21 に 渋谷区 から 千代田区 に変わったとします):
| 取引先 Key | 取引先コード | 取引先名 | original_取引先住所 | effective_date | current_取引先住所 |
|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都港区 | 2022-12-21 | 東京都千代田区 |
カラムから 渋谷区 の情報が消えてしまいました。
細かい亜種ですが、 original_ として最初に取り込んだときの住所を持ち続けるのではなく、前回の住所を追跡するために previous_ カラムを持たせるなどのアイデアも要件に合わせて採用することができます。
Type 3 の特徴
利点としては実装が簡単で管理コストが低い点です。分析利用の要件として限定的なスコープのみで変化を追いかけられればそれでよいという場合には、大掛かりな仕掛けを用意せずすみます。
欠点としては、たかだか有限なカラムの中でしか追跡しきれない点です。「実は後から全部の変更を追いかけたくなった」と利用者から問い合わせがあっても、DWH 側ではどうすることもできません。
SCD Type 4 ~ 7: 発展的な設計を学ぶ
余談: 最初期には Type は 3 までだった
Type 4 以降の説明をする前に豆知識を共有します。
実は、1996 年に提唱され広まった SCD Types では、その最初期の内容として含まれるのは上記の Type 3 までだったようです。Type 4 以降に関しては、SCD のアイデアが広まった後に有名になっていった個別のテクニックを、SCD の提唱者が改めてラベル付けして整理したものとなります。詳細な経緯についてはこちらのエントリを参照ください: Design Tip #152 Slowly Changing Dimension Types 0, 4, 5, 6 and 7 - Kimball Group
よって、まずは基礎となる Type 3 までを理解し、その上でハイブリッドなテクニックである Type 4 以降を調べるようにするとよいと思います。
また、高度な設計に関しては、スタースキーマに関する知識を前提とします。できるだけ平易な語用に努めますが、どうしてもファクトやディメンションといった単語が出てきます。それらの単語は理解されていることを前提とします。
スタースキーマに関する参考資料
SCD Type 4: ディメンションを履歴テーブルに切り出して急速な変化に対応する
なぜ Type 4 を採用するのか?
対象とするテーブルの中で、一部のディメンションが頻繁に変化するケースを考えます。この場合は、次の観点から Type 2, 3 どちらでも対応が難しいといえます:
- Type 2: 一部のディメンションの頻繁な変化につられて大量のレコードが発行されてしまう。なおかつ、レコードのユニーク制約もなくなるため、パフォーマンス悪化に繋がる
- Type 3: 短期間で状態が変わってしまうため、非常に限られた期間のデータしか追跡することができない。また、対応したいディメンション数に比例してカラムを増やす必要がある
そのため、より効率的な設計として Type 4 が考案されました。
Type 4 のアイデアは、頻繁に変化するカラム(対象のディメンション)を分離して「ミニ・ディメンション (mini dimension)」とも呼ばれる専用テーブルで管理する設計です。
こうすることで、変更履歴を管理するという関心事はミニ・ディメンションテーブル側に切り出せます。別のテーブルは、ミニ・ディメンションテーブルのキーをどう持つかだけを考えればよいことになります。
状態の変化するディメンションが新たにソーステーブルに追加されたとします。この場合にも、ミニ・ディメンションテーブルが影響を吸収してくれます。つまり、DWH 側としては、ミニ・ディメンションテーブルだけでソーステーブルのディメンション追加に対応すればよいことになります。
Type 4 の実装
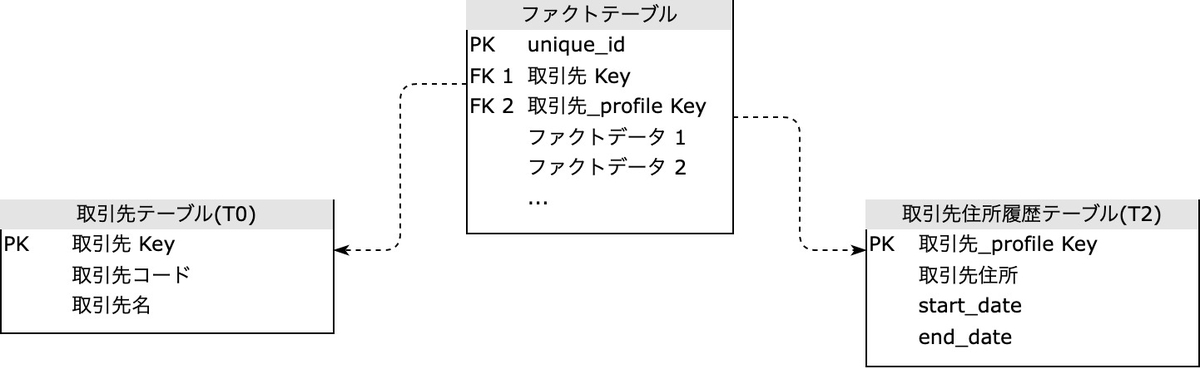
Type 4 の特徴は、テーブルをふたつ持つことです。ひとつめのテーブル 取引先テーブル は Type 1 として現在の状態を保持し、もうひとつのテーブル 取引先住所履歴テーブル は Type 2 として対象ディメンションの変更の履歴を保持します。
Type 1 取引先テーブル :
| 取引先 Key | 取引先コード | 取引先名 | 取引先住所 |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都渋谷区 |
Type 2 取引先住所履歴テーブル (ミニ・ディメンションテーブル):
| 取引先 profile Key | 取引先住所 | start_date | end_date |
|---|---|---|---|
| 1 | 東京都港区 | 2022-12-01 | 2022-12-11 |
| 2 | 東京都渋谷区 | 2022-12-11 | null |
こうすることで、住所が頻繁に変更されるような場合にもその対応を単一の Type 2 テーブルに隔離できるため、Type 1 テーブルのレコードの本来の増加要因である「取引先の追加」と負荷を分けて扱えるようになります。Type 1 取引先テーブル 側の 取引先住所 カラムを消してしまって、事実上の Type 0 テーブルにする設計も可能です。
ファクトテーブルとの結合の関係は、次の図のようになります:
Type 4 の特徴
利点としては、データの利用者は最新の状態を扱いたい場合は 取引先テーブル を、住所に関しての時間変化が欲しい場合は 取引先住所履歴テーブル を扱うなど、コンテキストを分けた利用により DWH への問合せの効率がよくなります。
欠点としては、利用者にふたつのテーブルがあるコンテキストを理解してもらう必要があるなど、分析システムとして複雑になる点が考えられます。
余談: SCD Type 5, 6, 7 をなぜ利用するのか?
基本的なユースケースについては、ここまで述べてきた Type 4 までの構成で対応できます。
その上で、この先紹介する Type 5, 6, 7 は何のためにあるのでしょうか?先にそのモチベーションを説明します。これらには共通の達成したい要件があります。それは、「過去のディメンションの変化を正確に保存しつつ、ファクトの時間推移を当時のディメンションと併せて適切に報告できる」というものです。そのために、いままで説明した基本的な構成をハイブリッドに組み合わせます。システムとしては複雑なものになりますが、より変化に頑健な DWH を構築することができます。
SCD Type 5: 履歴テーブルの内容を Type 1 で統合する
Type 5 は、Type 4 の発展系のような形を取っています。
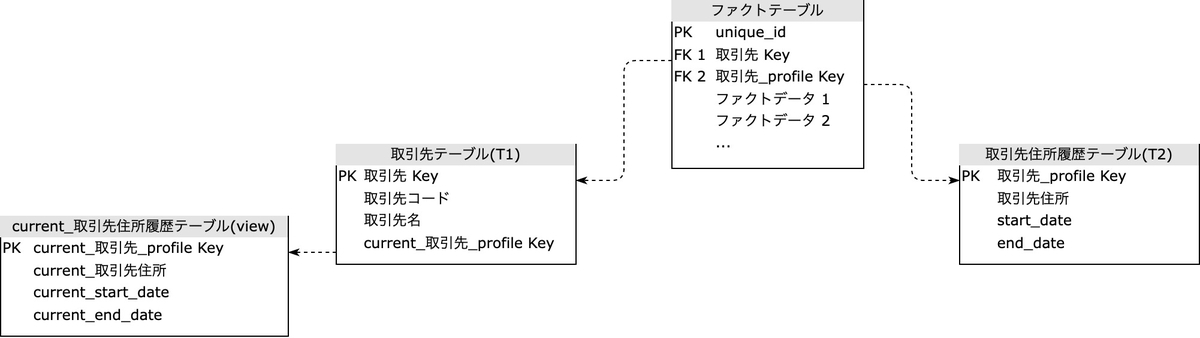
Type 4 と異なる点は、Type 4 で作成したミニ・ディメンションテーブル( 変更履歴テーブル )の最新レコードへのキーを Type 1 テーブル側で管理する点にあります。このため、4+1 = 5 の番号が付けられています。
Type 1 取引先テーブル :
| 取引先 Key | 取引先コード | 取引先名 | current_取引先 profile Key |
|---|---|---|---|
| 123 | ABC | ぐの不動産 | 2 |
Type 2 取引先住所履歴テーブル (ミニ・ディメンションテーブル):
| 取引先 profile Key | 取引先住所 | start_date | end_date |
|---|---|---|---|
| 1 | 東京都港区 | 2022-12-01 | 2022-12-11 |
| 2 | 東京都渋谷区 | 2022-12-11 | null |
ミニ・ディメンションの最新のレコード、またはそのサロゲートキー単体を指して「現在のプロファイル (current profile)」と呼びます。
また、Type 1 取引先テーブル は取引先に関する安定的で基礎的な属性値( 取引先名 など、Type 0 に相当するもの)を抱えることが期待されるため、ベースディメンションテーブルと呼ばれる場合もあります。
ファクトテーブルとの結合の関係は、次の図のようになります:
Type 5 亜種:最新ディメンションを Type 1 テーブルに丸ごと埋め込むアプローチ
クエリパフォーマンスを向上させるために、ベースディメンションテーブルで最新版のサロゲートキーだけを更新していくするのではなくて、ベースディメンションテーブルにミニ・ディメンションテーブルの最新レコードを直接埋め込んで更新するパターンを採ることもできます。
Type 1 取引先テーブル :
| 取引先 Key | 取引先コード | current_取引先 profile Key | current_取引先住所 | current_start_date |
|---|---|---|---|---|
| 123 | ABC | 2 | 東京都渋谷区 | 2022-12-11 |
Type 2 取引先住所履歴テーブル :
| 取引先 profile Key | 取引先住所 | start_date | end_date |
|---|---|---|---|
| 1 | 東京都港区 | 2022-12-01 | 2022-12-11 |
| 2 | 東京都渋谷区 | 2022-12-11 | null |
こうすることで、ファクトテーブルがディメンションを取得したい場合には 取引先テーブル を結合するだけで、取引先に関する最新の属性値を一通り得られます。
SCD Type 6: Type (1+2+3) の結合アプローチ
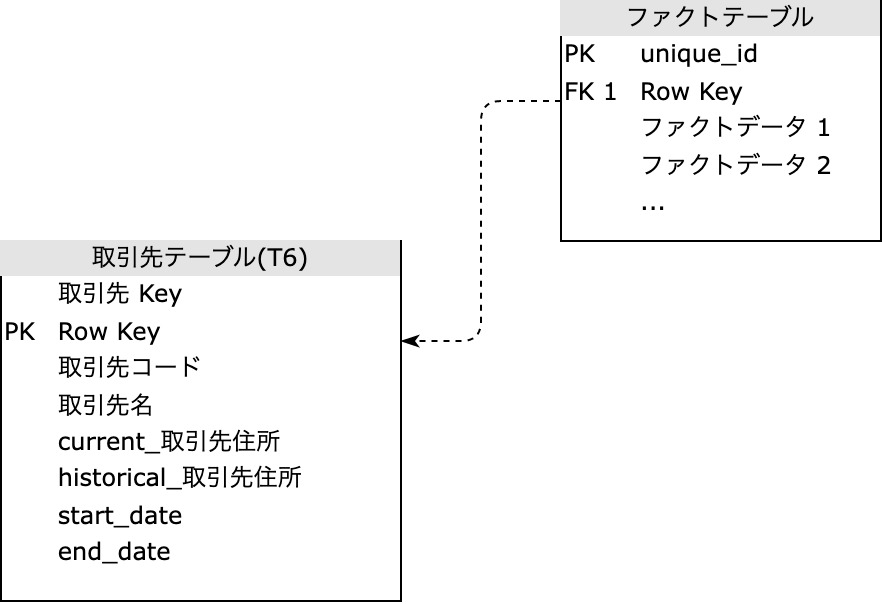
Type 6 は、先述の Type 5 とは大きく特徴が異なります。ひとつのテーブルで管理を完結させる設計になっているからです。そのテーブルの中で Type 1, Type 2, Type 3 それぞれの管理方法をすべて採用した更新方法をしているため、1+2+3 = 6 を番号に与えられた Type だといわれています。
具体的な流れを把握するのがもっとも理解に繋がると思いますので、Type 6 テーブルがどのように変化していくかの例を次に示します。
Type 6 の実装
取引先テーブル は、レコードがひとつある状態から始まります:
| 取引先 Key | Row Key | 取引先コード | 取引先名 | current_取引先住所 | historical_取引先住所 | start_date | end_date | current_flag |
|---|---|---|---|---|---|---|---|---|
| 123 | 1 | ABC | ぐの不動産 | 東京都港区 | 東京都港区 | 2022-12-01 | 9999-12-31 | true |
初期状態で current_取引先住所 と historical_取引先住所 は同じ 東京都港区 です。 current_flag = true はこのレコードが現在の状態であることを示しています。
ソーステーブル側で住所が 港区 から 渋谷区 に移転した場合、Type 2 と同様にレコードを新規追加します。ですが、ここでサロゲートキー 取引先 Key を更新するのではなく、 Row Key を更新して一意性を確保します。結果は次のようになります:
| 取引先 Key | Row Key | 取引先コード | 取引先名 | current_取引先住所 | historical_取引先住所 | start_date | end_date | current_flag |
|---|---|---|---|---|---|---|---|---|
| 123 | 1 | ABC | ぐの不動産 | 東京都渋谷区 | 東京都港区 | 2022-12-01 | 2022-12-11 | false |
| 123 | 2 | ABC | ぐの不動産 | 東京都渋谷区 | 東京都渋谷区 | 2022-12-11 | 9999-12-31 | true |
ここでは、次に述べるように Type 1, 2, 3 それぞれの設計に見られる特徴をすべて満たすような操作を行なっています:
- Type 1 処理:
Row Key = 1のレコードで、current_取引先住所は東京都渋谷区へ上書きする - Type 2 処理:
start_date、end_date、current_flagは Type 2 と同等の処理をする - Type 3 処理:
Row Key = 2のレコードで、historical_取引先住所に東京都渋谷区を保存する
さらに取引先住所が移転した場合(渋谷区 → 千代田区)、別のレコードを追加して、 current_取引先住所 カラムを上書きします:
| 取引先 Key | Row Key | 取引先コード | 取引先名 | current_取引先住所 | historical_取引先住所 | start_date | end_date | current_flag |
|---|---|---|---|---|---|---|---|---|
| 123 | 1 | ABC | ぐの不動産 | 東京都千代田区 | 東京都港区 | 2022-12-01 | 2022-12-11 | false |
| 123 | 2 | ABC | ぐの不動産 | 東京都千代田区 | 東京都渋谷区 | 2022-12-11 | 2022-12-21 | false |
| 123 | 3 | ABC | ぐの不動産 | 東京都千代田区 | 東京都千代田区 | 2022-12-21 | 9999-12-31 | true |
ここでは次のことが起こっています:
- Type 1 処理:
Row Key = 1,Row Key = 2のレコードで、current_取引先住所は東京都千代田区へ上書きする - Type 2 処理:
start_date、end_date、current_flagは Type 2 と同等の処理をする - Type 3 処理:
Row Key = 3のレコードで、historical_取引先住所に東京都千代田区を保存する
ファクトテーブルとの結合の関係は、次の図のようになります:
Type 6 の亜種
細かな設計の違いですが、亜種が存在します。Type 2 のように、 Row Key を持たずサロゲートキーをそのままインクリメントしてくパターンです。
| 取引先 Key | 取引先コード | 取引先名 | current_取引先住所 | historical_取引先住所 | start_date | end_date | current_flag |
|---|---|---|---|---|---|---|---|
| 123 | ABC | ぐの不動産 | 東京都千代田区 | 東京都港区 | 2022-12-01 | 2022-12-11 | false |
| 124 | ABC | ぐの不動産 | 東京都千代田区 | 東京都渋谷区 | 2022-12-11 | 2022-12-21 | false |
| 125 | ABC | ぐの不動産 | 東京都千代田区 | 東京都千代田区 | 2022-12-21 | 9999-12-31 | true |
このパターンでは、ファクトテーブル側でファクトの発生時刻に応じて適切なサロゲートキー 取引先 Key を保有しておく必要があります。それさえできていれば、サロゲートキーを join するだけで容易に当時のディメンションを取り出すことができるのが利点です。
ファクトテーブルとの結合の関係は、次の図のようになります:
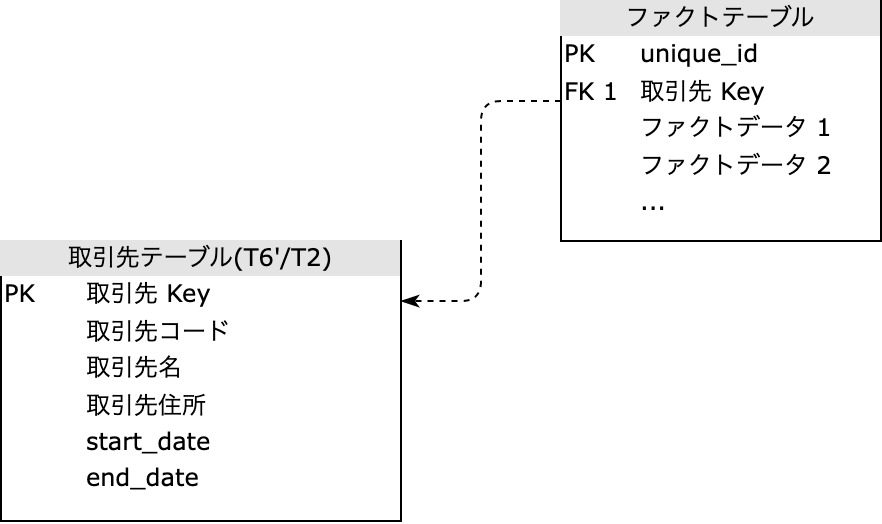
純粋な Type 6 設計では、ファクトテーブルはサロゲートキーとして固有の値(例における 取引先 Key = 123 )のみを持つため、join 時にはファクトの発生時刻から時間計算をして、適切なバージョンを選択する必要があるのが難点です。ですが、いくつかの利点も知られています。
この違いについての詳細な議論は Wikipedia の記述を参照ください: Slowly changing dimension - Wikipedia
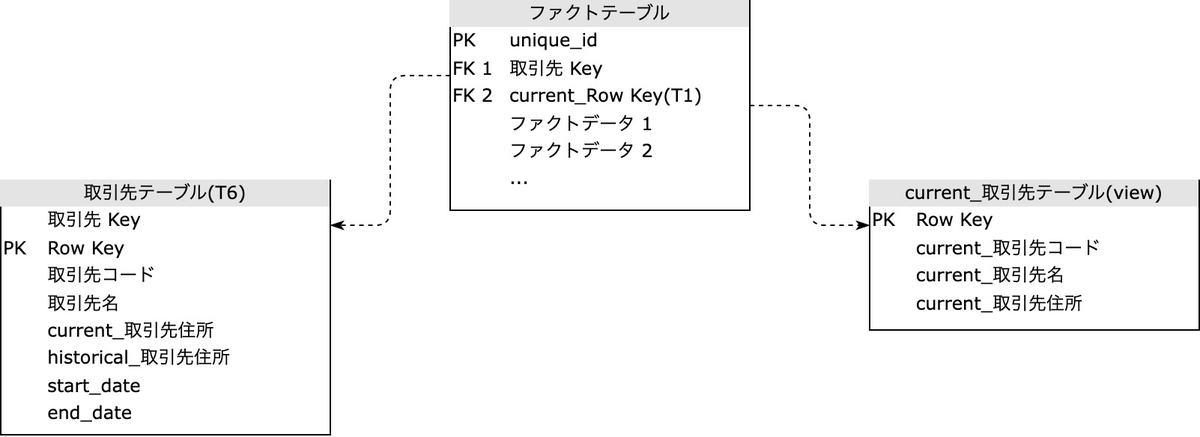
SCD Type 7: Type 6 からファクトテーブルでのキーの持ち方を工夫させる
Type 7 は、Type 6 と同じ設計を取ります。どこが違うのかというと、ファクトテーブル側でのキーの持ち方、結合のさせ方です。
Type 7 の実装
Type 6 の例と同じ状況を考えます:
| 取引先 Key | Row Key | 取引先コード | 取引先名 | current_取引先住所 | historical_取引先住所 | start_date | end_date | current_flag |
|---|---|---|---|---|---|---|---|---|
| 123 | 1 | ABC | ぐの不動産 | 東京都千代田区 | 東京都港区 | 2022-12-01 | 2022-12-11 | false |
| 123 | 2 | ABC | ぐの不動産 | 東京都千代田区 | 東京都渋谷区 | 2022-12-11 | 2022-12-21 | false |
| 123 | 3 | ABC | ぐの不動産 | 東京都千代田区 | 東京都千代田区 | 2022-12-21 | 9999-12-31 | true |
Type 6 を実装したディメンションテーブルがあるとき、一般的な実装として、ファクトテーブルはディメンションテーブルのサロゲートキー(例における 取引先 Key )のみを持ちます。
ですが、ここに追加して Type 6 テーブルの現在有効なレコードに一意なキーを、ファクトテーブルに追加で持たせるのが Type 7 です。例における Row Key = 3 に相当します。そうすると、ディメンションの更新の際にファクトテーブルを逐一更新する必要はあるものの、逆にディメンションテーブルで最新の値を更新しながら持つ必要はなくなります。
こうすると、ファクトテーブルからディメンションを結合したい利用者の便利さは増します:
Row Keyから最新のディメンションが得られる取引先 Keyと、ファクトの発生日とstart_date,end_dateとの比較からファクト発生当時のディメンションが得られる
ファクトテーブルとの結合の関係は、次の図のようになります:
まとめ
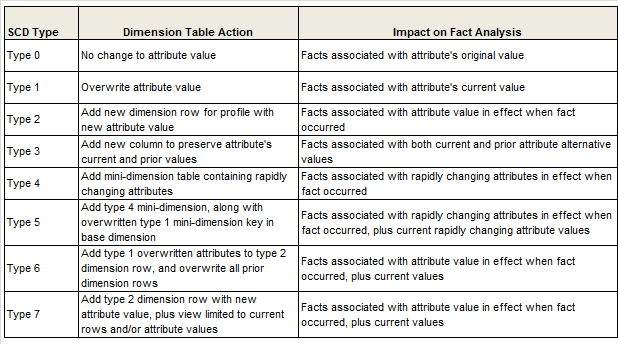
最後に、各タイプごとのまとめがありましたので、こちらを筆者が翻訳・一部改変して引用します:
| SCD Type | ディメンションテーブルでやること | ファクト分析への影響 |
|---|---|---|
| 0 | 値を上書きしない | ファクトは、属性値の最初の値と紐付く |
| 1 | 値を上書きする | ファクトは、属性値の現在の値と紐付く |
| 2 | 新しいディメンション行を追加して新しい値を保存する | ファクトは、発生したそのときに有効だった属性値と紐付く |
| 3 | 新しいカラムを追加して現在値と過去値を保持する | ファクトは、現在とその前の属性値の両方に紐付く |
| 4 | ミニ・ディメンションテーブルを追加し、急速に変化する属性値を保持する | ファクトは、発生したそのときに有効だった急速に変化する属性値と紐付く |
| 5 | Type 4 のミニ・ディメンションテーブルを追加した上で、上書きされる Type 1 のミニ・ディメンションへのキーをベースディメンションテーブル側へ追加する | ファクトは、発生したそのときに有効だった急速に変化する属性値と、それに加えて現在の急速に変化する属性値と紐付く |
| 6 | Type 2 のディメンション行に Type 1 の上書き対象の属性を追加し、それ以前のディメンション行をすべて上書きする | ファクトは、発生したそのときに有効だった属性値に加えて現在の属性値と紐付く |
| 7 | 新しい属性値で Type 2 のディメンション行を追加し、それに加えて現在の行に限定したビューを追加する | ファクトは、発生したそのときに有効だった属性値に加えて現在の属性値と紐付く |
ref: Margy Ross, Design Tip #152 Slowly Changing Dimension Types 0, 4, 5, 6 and 7 - Kimball Group
おわりに
本稿では、近年関心を集めている dbt プロダクトの中から、 dbt snapshot について取り上げました。さらに、Slowly Changing Dimension の Type 0 ~ 7 について、一通りの具体例を交えた解説をしました。
次回は m-hamashita さんの『突撃隣の作業環境2022(仮称)』となります。
引き続きよろしくお願いいたします!