この記事は Gunosy Advent Calendar 2023 の 9 日目の記事です。昨日の記事は koizumi さんの「インシデント発生時における初動対応の自動化」でした。
こんにちは、データサイエンス部 ML チームの大竹です。
弊社では KDDI 株式会社が提供するスマートフォン向け動画アプリ、au5Gチャンネルに対して動画コンテンツのレコメンドエンジンを提供しています。今回のブログでは、au5Gチャンネルのレコメンドエンジン開発をどのように進め、そこからどのような学びが得られたのか、パーソナライズド推薦モデルの構築にフォーカスしてその足跡を振り返りたいと思います。
全体観やシステム構成に関しては以下のブログも合わせて参照いただけると幸いです。
プロジェクトの背景
au5Gチャンネル は、音楽・アニメ・スポーツ・動物・レシピなどの多様なジャンルの動画を視聴できる動画アプリです。
今回のプロジェクト開始時にはすでにリリースがなされており、その段階では各ユーザーの興味に合った動画を表示することができないという課題を抱えていました。
そこでパーソナライズ推薦モデルを利用したレコメンドエンジンを導入し、よりユーザーの興味に関連したコンテンツが表示されるようにすることでユーザーの体験が改善するか、より具体的にはユーザーの平均動画視聴時間が向上するかを検証するためにプロジェクトがスタートしました。
以下では、事前調査から始め、A/Bテストを行ってレコメンドエンジンのリリースを行うまでの流れを順に追っていきたいと思います。
事前調査: サーベイとログ・コンテンツ分析
動画推薦手法のサーベイ
動画を対象にしたコンテンツ推薦については社内でほとんど知見が存在しなかったため、ますば動画推薦に関する既存手法の調査から始めました。 RecSys や SIGIR など、情報推薦や検索に関連する国際会議に採択された論文を中心にサーベイを行いました。
中でも注目したのは、YouTube 初の深層学習に基づいた動画推薦モデルである [Covington+RecSys'16] です。論文中で提案されているモデルは実用上の高速な推論に耐えるアーキテクチャを備えており、社内で過去に使用していたニュース記事推薦モデル*1でも参考にしていた論文であることから、社内の知見も豊富な手法でした。
ユーザーとコンテンツの基礎調査
次に、既存ユーザーやコンテンツの特徴を把握するための事前分析を行いました。
コンテンツの分析では、どのような属性が推薦モデルの特徴量として利用できるのか、またそれらの属性がどのような統計的な性質を持っているのか等を確認しました。 各動画にはタイトルや動画の説明文、カテゴリを表現するタグ(例:レシピ)などリッチなテキスト特徴が付与されており、初手としてこれらのテキスト特徴量を利用したモデルを検証することにしました。
また人気があるコンテンツの傾向を調査し、時間経過によって価値が減衰していくコンテンツ(例:今日のニュース動画)の存在などを確認しました。
ユーザー分析では、主にユーザーごとの視聴傾向を調査しました。 特にパーソナライズ推薦によって体験が向上すると期待されるユーザー(例:音楽動画好きなど好みがはっきりしているユーザー)を抽出し、どのような好みのタイプがあるのかを分析しました。
以降の実験を通して、これらのユーザーは推薦モデルの定性的な評価を行う際のサンプルユーザーとして使用しました。
動画推薦モデルの構築(オフライン実験)
ユーザーフィードバックの形式を考慮したタスク設定
au5Gチャンネルは、ユーザーがメインで動画を視聴するチャンネルにおいて、TikTok や YouTube Shorts のように表示される動画を上にスワイプしていくことで次の動画が現れるような UI を備えています。
このような UI においては、映画サイトにおける映画の 5 段階評価に代表されるような、動画コンテンツに対するユーザーの明示的な評価(フィードバック)を利用することができません。*2
また、(Shorts ではない) YouTube のように動画を視聴する前段階として「サムネイルをクリックする」というアクションが必要ないため、こうしたクリック行動からユーザーの興味を予測することも困難です。
このようなアプリの特徴を踏まえ、今回はユーザーが動画に満足していれば一定以上長く視聴し、不満足ならばすぐに動画から離脱するという仮定に基づいて、ユーザーが動画を一定時間以上視聴するかどうかを予測するタスクを設計しました。
したがってタスクの入力はユーザー(視聴したコンテンツの履歴として表現される)と推薦候補のコンテンツ、出力はユーザーがコンテンツを一定時間以上視聴する確率になります。
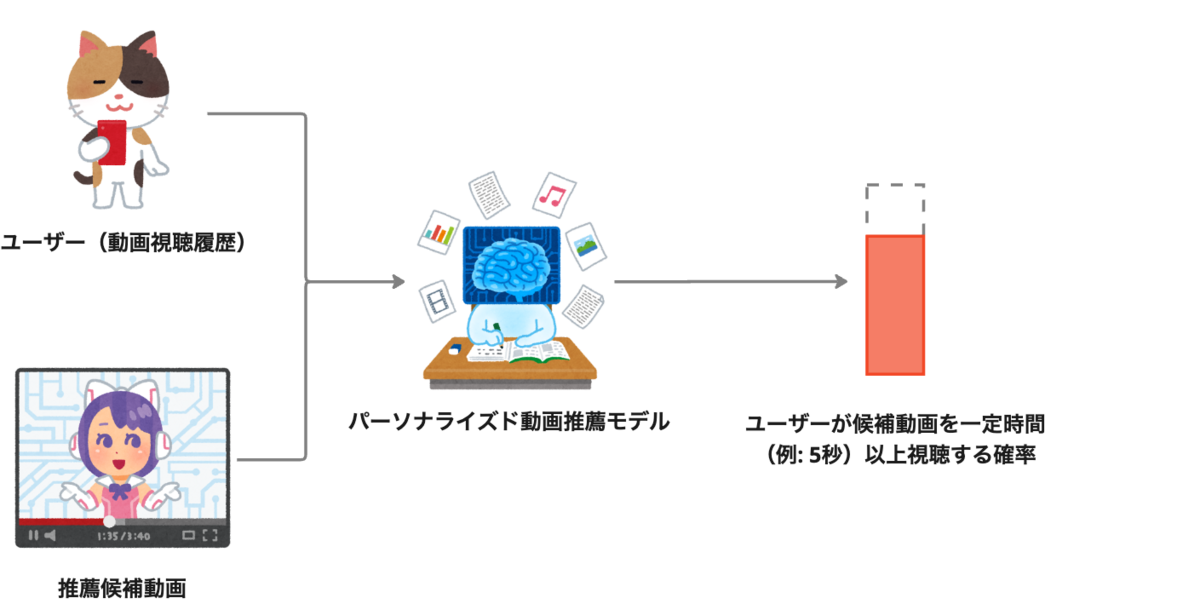
モデルアーキテクチャの決定
[Covington+RecSys'16] などを参考に、コンテンツエンコーダーとユーザーエンコーダーで構成され、各エンコーダーの出力するベクトルの内積によって推薦スコアの計算を行うモデルを設計しました。
ユーザーエンコーダーにおいては、ユーザーの視聴時間の長さに応じて視聴動画のベクトル表現を重み付けすることで興味の濃淡を考慮できるようになっており、各コンポーネントの詳細なアーキテクチャは実験を重ねながら探索していきました。

データセットの準備とモデル学習
学習・評価用のデータセットは既存ユーザーの視聴ログから構築し、バイアスを生む可能性がある超ヘビーユーザーのログを除去するといった前処理を行いました。 またデータセットを train / dev / test に分割する際には、時系列的な情報がリークしないよう、(例ですが) 1 月 ~ 6 月のログを train、7 月を dev、8 月を test とするような時系列的な分割を行うよう注意しました。
実験結果
ベースラインとして、現行のロジックを再現したもの、人気スコア(平均視聴時間)順との比較を行いました。 また、推薦モデルのスコアと人気スコアとの重み付け和によるアンサンブル手法*3との比較も行いました。
評価指標には、WatchTime@K(上位 K 個のコンテンツの平均再生時間)、および、一定時間以上視聴する/しないという情報を 2 値の適合度とみなして計算されるランキング評価指標として nDCG と MAP を使用しました。
| Method | WatchTime@1 | WatchTime@5 | nDCG | MAP |
|---|---|---|---|---|
| 現行のアルゴリズム | 100 | 100 | 100 | 100 |
| 人気順 | 118.5 | 113.7 | 99.9 | 99.8 |
| 推薦モデル単独 | 104.1 | 106.1 | 99.3 | 99.8 |
| アンサンブル | 124.4 | 114.8 | 101.5 | 103.4 |
実験結果の表は現行のアルゴリズムの値を 100% とした時の相対値を載せています。
主要な KPI である WatchTime@K に注目すると、現行のアルゴリズムと比較して、今回のモデル単独で平均再生時間が 4 ~ 6 % 改善することを確認しました。
人気順の強さが印象的で、単独では推薦モデルが人気順に劣ってしまっています。 しかしながら、推薦モデルと人気順のアンサンブル手法がもっとも良い評価となっており、推薦モデルが提供するユーザーの興味との関連度と、人気順が提供するコンテンツの全体人気度合いが互いに相補的な情報を提供し合っていることが分かります。
これらの結果を受け、アンサンブル手法をオンラインで実装することにしました。
オンライン実装・ A/B テスト
システム実装
実装したシステムアーキテクチャは、動画推薦 API、バッチシステム、コンテンツのクローリング、視聴ログの ETL を行うワークフローなどを含んでいます。 詳しくはこちらのブログを参照ください:動画アプリの推薦システムを開発しました @au5Gチャンネル
オンラインロジックの調整
オンライン実装を終え、A/B テスト開始前に実際のサンプルユーザーで推薦レスポンスを確認していた際、以下のような複数の課題が見つかりました。
- オフライン実験で決定した最適なアルゴリズムをそのまま適用すると、推薦が一部のカテゴリに大幅に偏ってしまう(多様性の低下)
- 対象ユーザーのコンテンツ視聴数が少ない場合、少量の視聴ログに推薦結果が引っ張られてしまう
- 対象ユーザーの興味とマッチしていても、人気スコアとのアンサンブルによって全体人気が低いコンテンツが推薦されない
それぞれの課題に対処するため、以下のような工夫を行いました。
- 同じカテゴリの動画が連続で表示されにくくなるように制御する
- ユーザーの視聴数が少ない場合は人気スコアの重みを大きくすることでパーソナライズの比重が大きくなりすぎないように制御する
- 人気スコアを考慮せず、推薦モデルの出力のみを使用した上位コンテンツを一定の割合で混ぜるよう制御する
また、先述した時間経過によって価値が減衰していくコンテンツ(例:今日のニュース動画)に対しては、コンテンツが公開されてから経過した時間に従って値が減衰する項を推薦スコアにかけ合わせることで価値減衰をモデル化していたのですが、この減衰項のパラメータ調整なども同時に行いました。
上位に推薦されるコンテンツの平均再生時間などの定量的な指標と定性的な推薦リストを観察しながらの最終調整で、当初の見込みよりも長い時間を要しました。
リリース・A/B テストの実施
推薦結果の定性的なチェックやシステムとしての単体・結合テスト・負荷試験を行った後、A/B テストを開始し、今回開発したレコメンドシステムの有効性を検証しました。
結果として、主要な KPI である平均再生時間が大幅に向上し、プロジェクトの目的を達成することができました。
オフライン実験で確認していた改善幅よりも平均再生時間が大きく向上している点が興味深く、厳密な理由の分析は難しいものの、オンラインで行った推薦アルゴリズムの調整でオフライン実験時よりも良い推薦ができるようになった可能性はありそうです。
振り返りとまとめ
ゼロから推薦システムを構築するのは初めての経験で非常に学びが多かったです。
特に以下の2点はプロジェクト開始時の想定と大きく異なっており深く印象に残りました:
- オフラインで定量的な効果を確認できたアルゴリズムが実際にユーザーストーリーを満たすようなアルゴリズムであるとは限らないこと(実際には追加で様々な微調整が必要になる)
- ニュース記事推薦で培った知見がそのまま生きる場面もある一方で、ニュース記事 → 動画 と推薦するドメインが変わることで様々な新しい課題が出現すること(例:長い動画ほど長く視聴されやすいというバイアス)
今回はタイトなスケジュールで開発を行ったため、時間があれば取り組みたかった改善点が依然たくさん存在しています。 今後もより良い推薦を目指してアルゴリズムの改良を続けていく予定です。
次回は kmurata さんの XXX です!お楽しみに!
*1:https://data.gunosy.io/entry/news-recommendation-model
*2:「お気に入り」機能のような明示的なフィードバックが存在する場合もありますが、こうしたフィードバック機能のログが推薦モデルの学習に利用できるほど十分に集まるケースは多くありません。
*3:重みはグリッドサーチにより探索を行いました。