こんにちは。Gunosy TechLab MediaMLチーム所属の桾澤 (@gumigumi4f) です。
この記事では、弊社で配信しているニュースアプリであるグノシーのパーソナライズアルゴリズムを刷新した話について書きたいと思います。
アーキテクチャの部分まで含めて記事にしてしまうと非常にブログが長くなってしまうので、本記事ではリアルタイム性の高い重要なニュース記事についてどのようにレコメンドするかについて注目して述べます。 アーキテクチャの部分についてはブログ後編のアーキテクチャ編にて書きたいと思います。
後編はこちら
ニュースアプリのパーソナライズ
グノシーというニュースアプリでは、ホーム画面からのアプリ起動時に必ず「トピック」というタブが表示されます。
この「トピック」というタブは各トピックに沿った記事を配信する「エンタメ」や「スポーツ」というタブと異なり、「流行っているニュースや興味があるニュースがひと目で分かる」を目指したタブになっています。
グノシーを利用するユーザーの大半はこのトピックタブを主に使用するので、トピックタブにおけるユーザー体験を向上させることがユーザー満足度の向上、ひいてはRRの向上に重要です。
ところが、ニュースの推薦というのは他分野の推薦とは異なりコールドスタートとよばれる問題を解決しなければなりません。
映画や音楽など推薦ではログを十分にためてからそのログを元に推薦を行うことが可能です。 一方、ニュースは時間の経過とともにニュースの価値が低下します。 そのため、ログが溜まるのを待ってから学習、推薦を行うと、古い情報のみがリストに並ぶことになってしまいます。
このようにログが十分に無いときに適切なレコメンドが行えない問題はコールドスタート問題と呼ばれ、ニュースのレコメンドにおいて非常に重要となります。
このあたりの話は以前発表している内容ですので、こちらを参照してもらえるとよりわかりやすいかなと思います。
このような理由から、ニュースアプリの推薦システムは他の分野の推薦に比べて難しい課題であると言えます。
グノシーにおける旧来のパーソナライズアルゴリズムとその課題
弊社では2017年前後からパーソナライズに力を入れ始め、グノシーにおいても2018年にパーソナライズを全ユーザーに対して適用しています。
2018年に適用したロジックはクラスタリングをベースとしたロジックとなっています。*1
具体的には以下のような流れでパーソナライズを行うロジックになっています。
- ユーザーがクリックした記事の内容語を元にユーザーを一定のクラスタ数にクラスタリング
- クラスタに所属するユーザーのImpression, Clickを集計しクラスタ毎に記事のCTRを算出
- ユーザーからのリクエストに対してユーザーの所属するクラスタで流行っている記事 (CTRが高い記事) を返却する
厳密には他にも細かいことをやっているのですが、大まかな説明としてはこのようになります。
この既存のアルゴリズムでは以下の問題が存在します。
- ユーザー個々人にあった記事の配信ができていない
- CTRをベースにしたパーソナライズアルゴリズムであるため、CTRが高くなってしまう扇情的な記事がリスト上部に並びやすくなる
1.についてはパーソナライズの粒度がクラスタ数に依存していることが大きな理由です。 クラスタリングを用いたパーソナライズの場合、クラスタ数を多くしすぎるとクラスタあたりのユーザー数が少なくなってしまうため、CTRの集計に必要なサンプルサイズが足りなくなってしまいます。 逆にクラスタ数を少なくした場合はパーソナライズの粒度が落ちてしまい、大雑把なレコメンドしかできなくなってしまうという問題があります。
2.についてはあまり問題に感じないかもしれませんが、現状グノシーにおいてはこちらのほうが大きな問題となっており、直近で集中的に取り組んでいる問題となっています。
グノシーに入稿される記事の中には、人間の本能的な部分に訴えかけクリックさせてしまう記事が少なからず存在します。 これは例えば「エロいサムネで男性の本能に訴えかける記事 (中身はいうほどエロくない)」であったり、「人気芸能人のスキャンダルを匂わせる記事 (実際はくだらない内容)」であったりするのですが、そういった記事は興味がなくても自然と指が記事をタップしていたりするものです。
これらの記事は内容に反してCTRが高くなりやすく、CTRが高い記事が上位に出やすくなる既存のアルゴリズムでは、どうしてもエロい記事や扇情性を煽る記事がリストの上位に出てきがちになります。 このような記事ばかりを推薦するとユーザーの満足度を落とすどころか、アプリのブランディング的にもよろしくありません。*2
グノシーの新しいパーソナライズアルゴリズム
今までの説明を踏まえ、新しいアルゴリズムは以下の制約に基づき開発を行いました。
- 既存ロジックよりも扇情性の高い記事が露出しない
- ユーザーの閲覧ログを元に個々人にあった記事を推薦する
以上の制約のもと、以下のようなモデルを構築しました。
まず、ユーザー が記事
をクリックする確率について
と変形することができます。
この式では、記事 そのものがクリックされる確率項
と記事
とユーザー
が共起度合いを表す項 (自己相互情報量 PMI) に分解することができました。
記事 そのものがクリックされる確率
はユーザー数がある程度いれば、以下のようにして計算することが可能です。
つまり、記事 とユーザー
が共起する度合い
を何かしらの方法で求めることができれば、ユーザーに対して適切なリストを返却することが可能になります。
ところで、PMIといえば自然言語処理においては単語と単語がどのくらい共起するかを図るための重要な指標であることが知られていますが、実はWord2VecはPMIの行列を低次元に落とし込んだものだということが理論的に証明されています。*3 これは、例えば単語「りんご」と単語「バナナ」のPMIをWord2Vecで学習されたベクトルの内積演算によって求めることが可能ということです。
Word2Vecでは周辺に出てきた単語から中心単語を予測するモデル (CBOW)と対象の単語から周辺単語を予測するモデル (Skip-gram) が存在します。 *4 今回開発したモデルではWord2VecのCBOWに習い、ユーザーの閲覧記事からユーザーが実際にクリックした記事を予測するような形となっています。
これによってユーザーの閲覧記事から生成されるベクトルと、候補記事のベクトルの内積演算によって、リアルタイムなニュースのパーソナライズが可能になっています。
実際のユーザーからのリクエストに対しては、バッチ処理によって事前に計算される と、リクエスト毎に候補記事とユーザーのベクトルの内積によって求められる PMI
によって、スコア
を計算し適切なリスト面を返却しています。
以下がモデルの図となります。
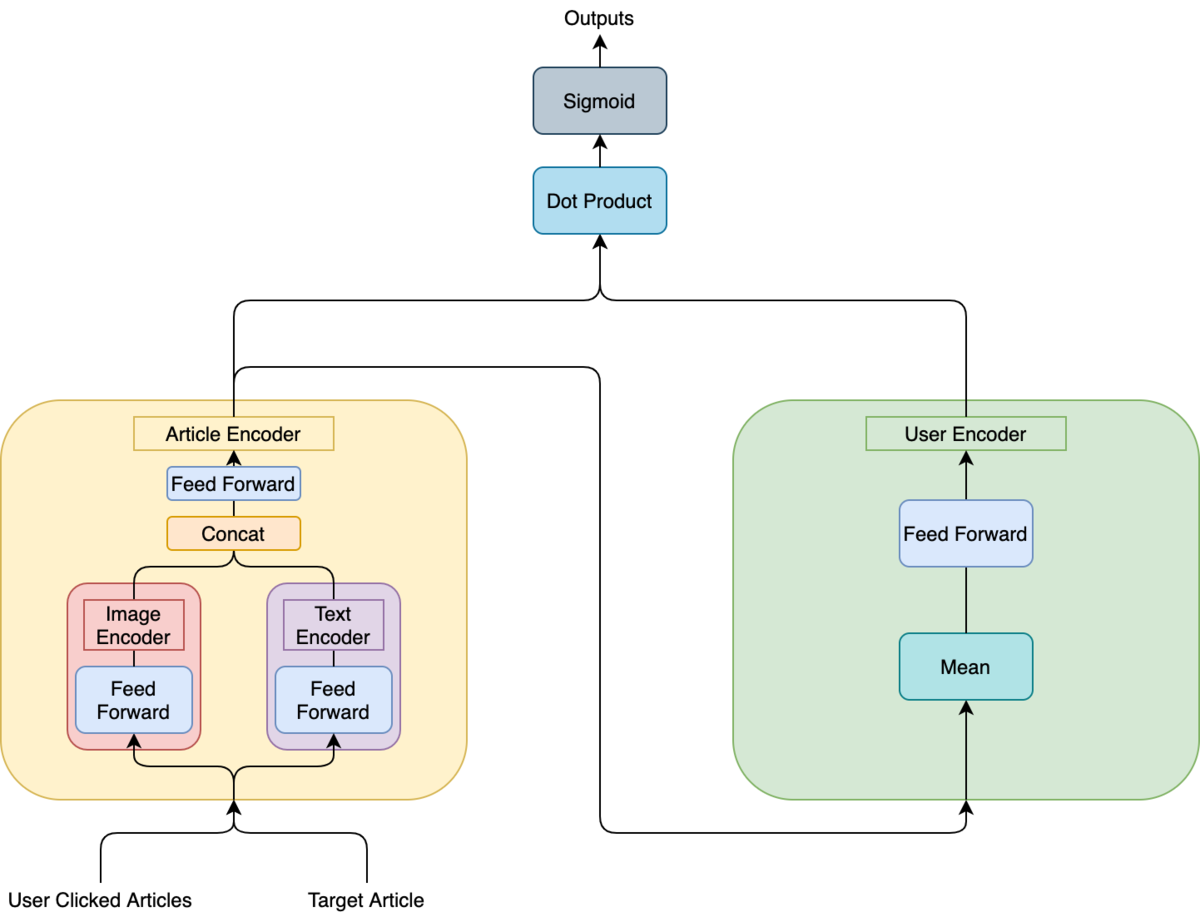
入力として "User Clicked Articles" と "Target Article" が存在すると思いますが、これはそれぞれ「ユーザーが閲覧した記事群」と「クリックしたかを学習するための対象の記事」を指します。 Word2VecのCBOWでいうところの「周辺単語」と「中心語」になります。
モデルを見ると入力された記事はまず"Article Encoder"を経由して低次元のベクトルに圧縮されます。 "Article Encoder"の中には"Image Encoder"と"Text Encoder"が存在します。
通常のWord2Vecであれば単語IDに対応したベクトルを引っ張ってくる部分ですが、ニュースアプリの推薦システムの場合はコールドスタート問題に対応する必要があるため、ニュース記事の特徴量から動的にベクトルを生成しています。 今回のモデルではニュース中のタイトルと本文先頭2文、ニュース中に存在する画像を特徴量として記事ごとに512次元のベクトルを生成します。
「中心語」に相当する "Target Article" はそのまま予測対象の単語として出力されますが、「周辺単語」に対応する "User Clicked Articles" は [窓幅分の次元, 512次元] のベクトルになっているためこれを512次元に落とし込むために "User Encoder" に通します。 ここはCBOWと同様に各ベクトルの平均を取った後、Feed Forwardを通すような形にしています。
最終的に出力された記事とユーザーのベクトルの内積を取りそれらをSigmoidに通して0, 1の出力にします。 それに対して、実際に出現した「中心語」である場合は1、Negative Samplingを用いてサンプルされた負例に対しては0を予測するように学習を行います。
これによってユーザーと記事がどの程度共起するかを記事の特徴量から計算できるようになっています。
オフライン実験とA/Bテスト
まずは作成したモデルの精度についてオフライン実験にて検証しました。
訓練データは2020/03/01から2020/04/29までの約二ヶ月間について10%サンプリングし生成しました。 NegativeSamplingでは1正例あたり5負例をWord2Vecでも用いられている分布*5に基づきサンプルしています。
まず定性的に記事が正しく低次元に埋め込みできているかを確認するため、t-SNEを用いて記事ベクトルを2次元に圧縮し描画しました。
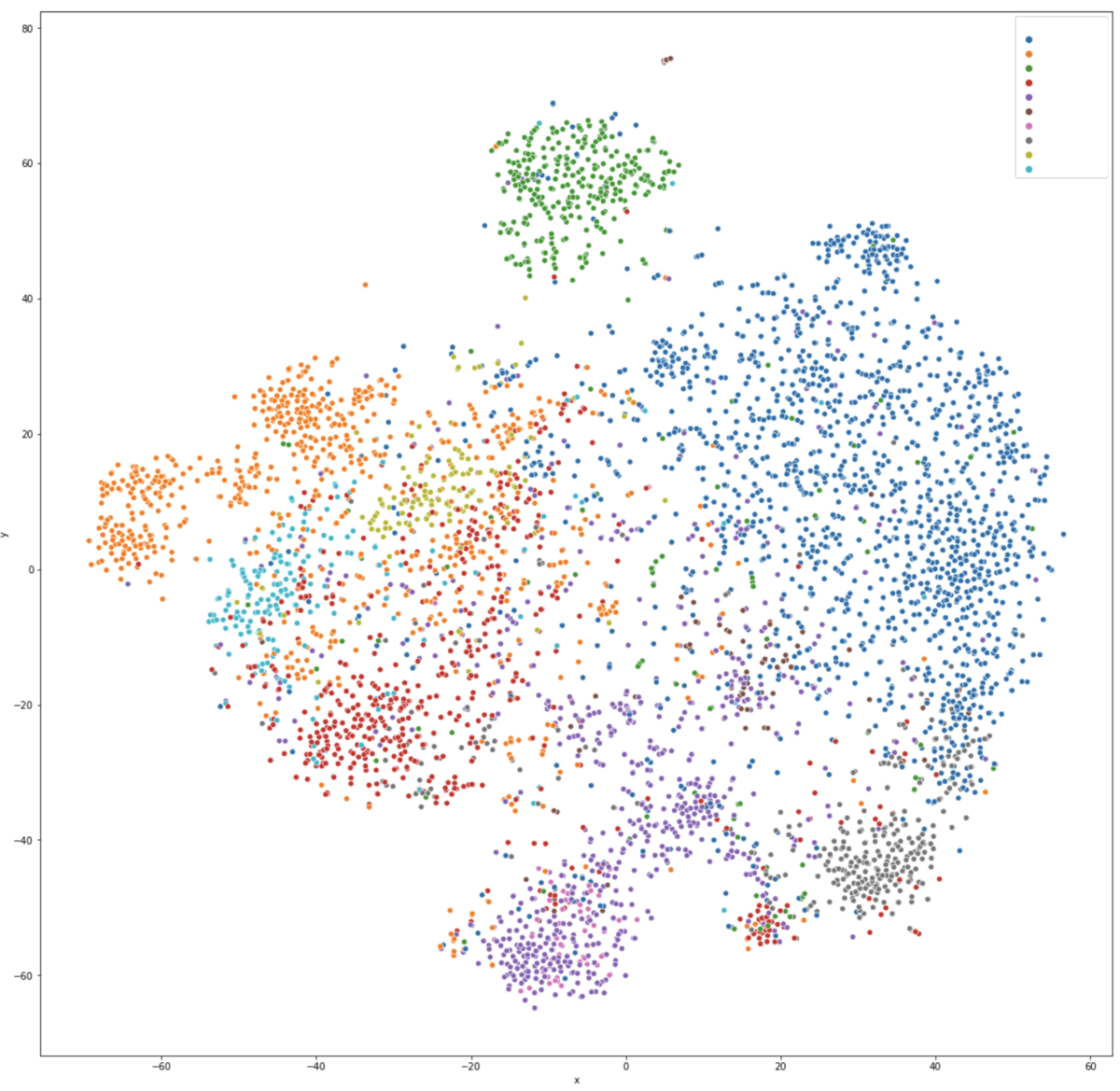
各色がグノシーのカテゴリーに対応しています(各色とカテゴリーの対応はわからないように隠しています)。 画像を見ると、カテゴリーが大まかに分かれてはいつつも、一部のカテゴリーとカテゴリーが密接に関係している等の特徴がわかります。
定量評価に関してはAUC, nDCGと別プロジェクトで作成した記事品質判定ロジックにて、扇情性が高いとされている記事がどれくらい上位に出てくるかを表した扇情スコアの3つで評価を行いました。 テストデータは2020/04/30のデータとなっています。
結果は以下のようになりました。
| Method | AUC | nDCG | 扇情スコア |
|---|---|---|---|
| 既存手法 | 0.6371 | 0.09262 | 0.069353 |
| 提案手法 | 0.6618 | 0.09226 | 0.063566 |
AUCでの評価は0.025ポイントの向上と改善幅が大きい一方で、NDCGでの評価では若干ですが数値を落とす結果になってしまいました。 しかしながら、扇情的な記事の露出が減っており推薦記事の全体的な質の向上が見込めるため、オンラインでのA/Bテストを実施しました。
結果として、提案手法でパーソナライズしたトピック面において、ユーザーあたりのクリック数が3%前後向上していることが確認できました。 また、定性的ではありますが、以前よりもエロい記事が上位に上がってくることが少なくなり、リスト面の品質が向上していることを確認しました。
おわりに
今回はグノシーのパーソナライズアルゴリズムを刷新した話を解説しました。
この記事では触れられなかったアーキテクチャ周りの話はまた別の記事で解説したいと思います。 数百万オーダーのユーザーからのリクエストに対してどのように高速にリクエストを返却しているのかなどを詳しく記載する予定です。
*1:https://arxiv.org/abs/1909.01005
*2:別プロジェクトでこのような記事を判定するロジックも実装しており、言語処理学会にて発表予定です
*3:元論文: https://www.aclweb.org/anthology/Q16-1028/ 解説: https://www.slideshare.net/MasatoNakai1/word2vec-70193656
*5:http://tkengo.github.io/blog/2016/05/09/understand-how-to-learn-word2vec/#negative-sampling