こんにちは。ML チームの 大城(k.oshiro)です。
こちらの記事は Gunosy Advent Calendar 2024 - Adventar の 5 日目の記事です。 4 日目の記事は nagayama さんの Android Push 通知の Tips - Gunosy Tech Blog でした。
本記事では私が今年取り組んだプロジェクトの 1 つである「まとめ動画作成効率化プロジェクト」について、振り返りも兼ねてまとめました。
まとめ動画について
Gunosy が開発している auサービスToday と ニュースパス には、1日に1本、今日の主要なニュースをまとめたスライドショー(動画)が配信されており、この動画を「まとめ動画」と呼んでいます。

まとめ動画は、編成・運用チームが記事の選定や動画キャプションの作成を行なっています。 この作業は毎日行われるもので、月に 百数十 時間ほど費やされていました。
このまとめ動画の大まかな作成フローは以下の通りで、このうち 1 ~ 3 が作業時間の 7 割を占めています。 今回のプロジェクトでは、「1. ニュース選択」と「3. キャプション作成」の支援を LLM を用いて行いました。
- ニュース選択と表示順の決定
- 関連する写真のピックアップ
- ニュースのキャプション作成
- 動画化(スライドショー)
- 内容のチェック
プロジェクトの流れとやったこと
本プロジェクトで求められる最終的なアウトプットとしては、候補記事とその見出しやキャプションを編成・運用チームの方が確認できるように提示する何かしら、となっており自由度が高くなっていました。
アウトプットの構成として、候補記事選択 → 見出し・キャプション生成という流れになるのですが、クリティカルな要素としては LLM を使ったキャプション生成というところになり、そのためのプロンプト作成から開始しました。
プロジェクトの流れとしては以下のようになりました。
- 見出し、キャプションを生成するプロンプトの作成とチューニング
- 候補記事選択
- バッチ処理の実装
- 運用とフィードバック & 改善
プロンプト作成とチューニング
このプロジェクトの根幹として、 LLM を使ったキャプション生成がうまく行えないといけません。 そこで、まず初めに過去に実際に使用された数記事を対象としてキャプションを生成する実験を行いました。 シンプルな文章要約タスクではあるのですが、まとめ動画の見出し・キャプションには様々な制約があり、その制約を考慮した出力にする必要がありました。
まとめ動画用の要約タスク設計
- 入力: 記事タイトル & 本文
- 出力: 見出し & 整形された要約文
- 見出しは 17 文字程度
- キャプションは 100 文字程度
- 「最大 17 文字 x 2 行の 1 文」x 3 文が基本構成
- 「最大 17 文字 x 4 行の 1 文」と「最大 17 文字 x 2 行の 1 文」の組み合わせでも可
始めに GPT-4 を使用し、GPT-4turbo や GPT-4o などを使用してキャプションの生成結果がどのように変化するのかを確認しました。
実験にて GPT-4 を使うよりも GPT-4o を使う方が文字数をある程度考慮できるようになっていることがわかり、最終的には GPT-4o を使うようにしました。
また、記事のカテゴリごとに過去のキャプションを与えることで、表現が少し良くなる傾向が見られました。 まとめ動画では重要なニュースを取り上げるため、結婚発表や事件事故などのある程度類似したパターンがあります。 このため、今回はカテゴリごとに出力例を与えることで、LLM による要約結果のブレを抑えることができたと考えています。
候補記事選択
まとめ動画に使用する記事はなんでも良いというわけではなく、重要なニュースに絞られています。 この重要なニュースに近いものとして、アプリ上ではヘッドライン記事というものがあり、こちらも編成・運用チームの方が人手で登録しています。 今回は、このヘッドライン記事を元に、前日の夜から当日直前までの記事を人気 (CTR) 順に並べて 3 記事ほど取得することで候補記事とするようにしました。
バッチ処理の実装
Gunosy では基本的に Slack 上でやり取りがされており、まとめ動画の候補記事やキャプションも Slack に投稿して共有&確認が行われています。 そこで、候補記事やキャプションを自動的に投稿するための専用チャンネルを Slack に作成し、自動投稿するバッチを作成することにしました。
以下はバッチ処理の内容を図にしたものです。
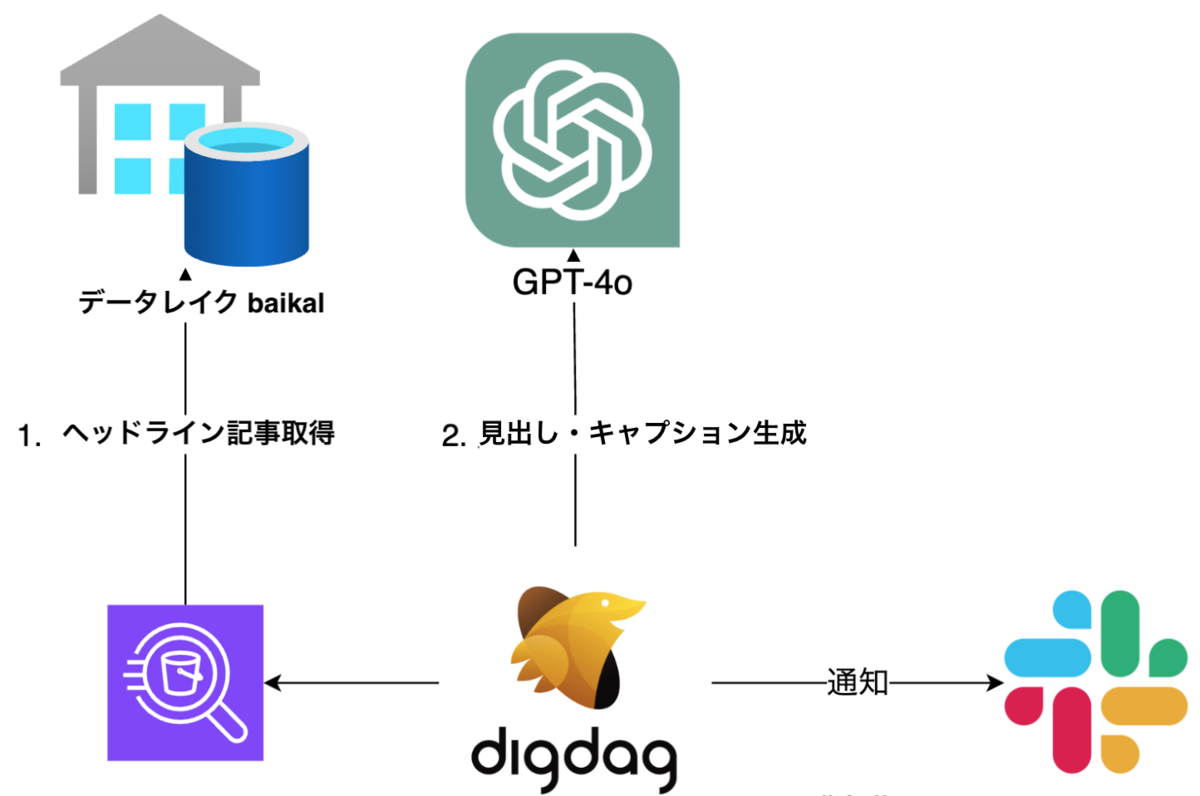
まず、候補記事としてヘッドライン記事からカテゴリごとに 3 記事選択します。 ここは Gunosy のデータレイクである baikal *1 から Athena を使ってヘッドライン記事を取得するようになっています。
次に、ChatGPT を用いて見出しとキャプションの候補を生成します。 こちらは OpenAI API を python から呼び出すように実装しました。
最後に、ChatGPT の出力結果を整形して Slack に投稿する部分を作成したら完了です。
このバッチを digdag で定期実行するようにして、編成・運用チームの作業開始前に Slack に通知を送るようにしました。
運用とフィードバック & 改善
DX プロジェクトの醍醐味である運用&改善フェーズでは、何度かフィードバック会を開催して編成・運用チームからいくつかの改善点や追加の要望をヒアリングしました。
フィードバックにはプロンプトの軽微な変更から、アドホックにキャプションを生成したいという要望まで様々なものがあり、 ![]() id:skozawa さんに相談しつつ優先度を決めて対応を行いました。
id:skozawa さんに相談しつつ優先度を決めて対応を行いました。
追加で streamlit を使った web アプリケーションの開発などもありましたが 最終的に 5 割の作業時間短縮が行えたというフィードバックを頂けました。
振り返り
自分自身である程度の主導権を持って進める初めてのプロジェクトだったため、かなりの不安がありましたが、マネージャーやチームメンバーの支えのおかげで最後まで走り切ることができました。
また、業務支援プロジェクトでは導入したものの使ってもらえないことが一番の懸念点となります。 本プロジェクトでは編成・運用チームが作業を効率化するためにフローの変更も受け入れてくださったことが、かなり重要な成功要因だと考えています。
改善点としては、LLM の実験評価を人手で細かくやっていた点が挙げられます。 実験対象を数記事に絞っているとはいえ、複数回実験を行うと評価に時間がかかっていました。 エンジニア以外の方がプロンプトの修正を行えるようにする一歩としても、評価の自動化ができると良いと考えています。
まとめ
この記事では LLM を使った業務支援プロジェクトについて振り返りを行いました。
この記事が LLM を用いたプロジェクトの参考になれば幸いです。
明日は johnmanjiro さんの 「CloudFront + S3 Object LambdaでHTMLをPDFに変換して配信する」 です。お楽しみに!
*1:baikal についての詳しい内容はこちらに書かれています。