はじめに
こんにちは!Gunosy Tech Labのコウ(@yuanzhi.ke)です。2020卒です。9月にようやく博士課程を修了し、正式に入社させていただきました。今はグノシーのクーポン推薦のロジック開発をしています。
こちらの記事は Gunosy Advent Calendar 2020 の4日目の記事です。 昨日の記事は片木(@jkatagi)さんの AWS Gamedayに参加した話 でした。
今日の話は、クーポンロジックの改善についての話です。とはいえ、僕はIR分野のサマースクールを一回参加ぐらいの経験しかなく、入社当時は推薦システムの分野の初心者です。この記事では、クーポンロジックの改善のために、初心者である僕のサーベイと感想をできるだけわかりやすくまとめてみました。間違ったところや不明なところがあれば、コメントください。
クーポン推薦について
皆がご存知でしょうと思いますが、弊社のアプリ製品グノシーではクーポンも提供しています。クーポンタブ内のクーポンの並び替えは、どう最適化するかは我らのチームの研究の対象です。
グノシーのクーポン推薦には以下のような課題があります:
- 他社のような商品購入記録や商品レビューがなく、ユーザーの好みやこだわりなどを捉えにくい;
- クーポンのタイトルと本文は短いので、記事より言語情報が少ない;
- 記事かクーポンのどちらかを利用するユーザがいるため統一のモデルの利用が難しい;
これまでは試行錯誤を重ねて練り出した推薦ロジックを使いましたが、肥大化してきているので、これから深層学習の力を借りて、ユーザーごとの並び替えのロジックを調整してもらうかと検討しています。
どのような推薦モデルがあるか
機械学習による推薦の既存モデルを、それぞれの使う特徴量のタイプから、一般的に以下の三種類に分けます:
- Collaborative Filtering:「この商品を見たユーザーがこの商品も見た」という感じでユーザーとアイテムのインターアクションを学習する手法
- Content-based Filtering:「このユーザーが今この商品が欲しいだろう」という感じで、ユーザーの直近の操作と時間帯などの情報から意図を予測できるように学習する手法
- ハイブリッド:以上二種類のモデルの学習目標を一緒に学習する手法
Collaborative Filteringの計算は軽く、実サービスにとって一番使いやすいでしょう。特にBPRがシンプル且つパワフルです。BPRの誕生は2009年ですが、今年でも、Collaborative Filteringの界隈なら、深層学習を使うNeural Collaborative FilteringでもBPRに負けると言及している論文があります。とはいえ、近年の各コンテストの結果では、ほぼ深層学習ベースが優勝しています:
- Microsoft News Recommendation Competition (2020)
- Santander Product Recommendation(2016)
- Coupon Purchase Prediction(2015)
- 1位〜4位の手法がわからない
- 5位はGBM
他には、Content-based Filteringのほうが、探索的データ分析から得る知見と特徴エンジニアリングの工夫を入れられるので、数値を出しやすいかもしれない。 「ユーザーの今のニーズ」の推測ができれば、単なる過去の記録と似ているユーザーの記録からの推測より柔軟な対応をできるでしょう。
クーポンのパーソナライズはどうするか?
冒頭で紹介した通り、クーポンの推薦では、特別な問題があります。従って、既存手法は論文の通りに効く保証がありません。そのため、我らがまず既存手法からいくつを選んでオフライン実験を行いました。
ここで、ベースラインをCTR順で設定します。そして、実サービスのコストとレスポンスタイムを考えて、まず計算が軽いモデルを試しました。結果は以下になります:
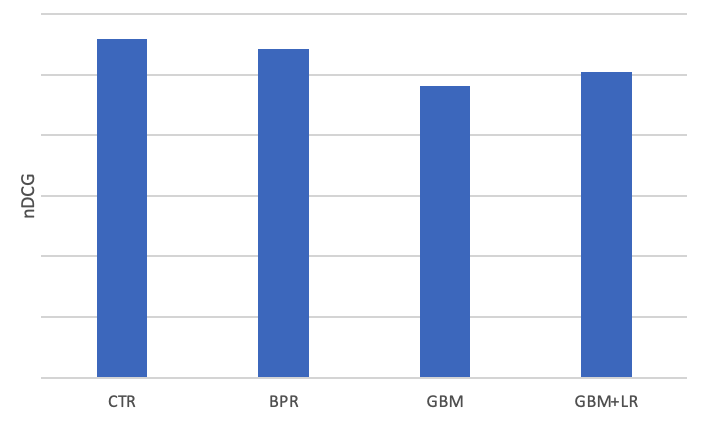 使ったサイド特徴量が少ないので、BPR > GBM+LR > GBMのはほぼ想定通りですが、すべて単純なCTRに負けました。やはりクーポンの学習は難しいです。
使ったサイド特徴量が少ないので、BPR > GBM+LR > GBMのはほぼ想定通りですが、すべて単純なCTRに負けました。やはりクーポンの学習は難しいです。
その後、汎化能力がより高い深層学習系のモデルに着目し、比較的に実装しやすいWide & Deepを試しました:
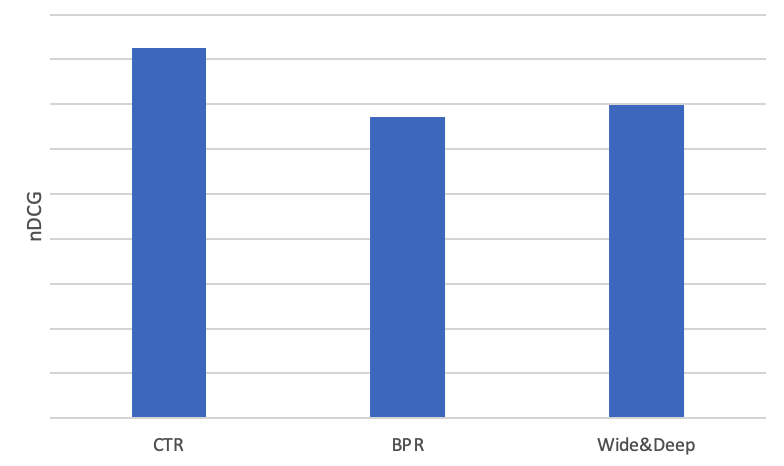 BPRよりいい結果出ましたが、CTRにまた負けましたね。ここの実験データでは、まだログ溜まっていないユーザーのログも使用、クリック数の少ないユーザに対する予測はコールドスタート問題があり難しいので、全体的な数値を見れば、BPRとWide&Deepが悪くみられるでしょう。そのため、アクティビティが高い一部のユーザーのみのログでも比較してみました:
BPRよりいい結果出ましたが、CTRにまた負けましたね。ここの実験データでは、まだログ溜まっていないユーザーのログも使用、クリック数の少ないユーザに対する予測はコールドスタート問題があり難しいので、全体的な数値を見れば、BPRとWide&Deepが悪くみられるでしょう。そのため、アクティビティが高い一部のユーザーのみのログでも比較してみました:
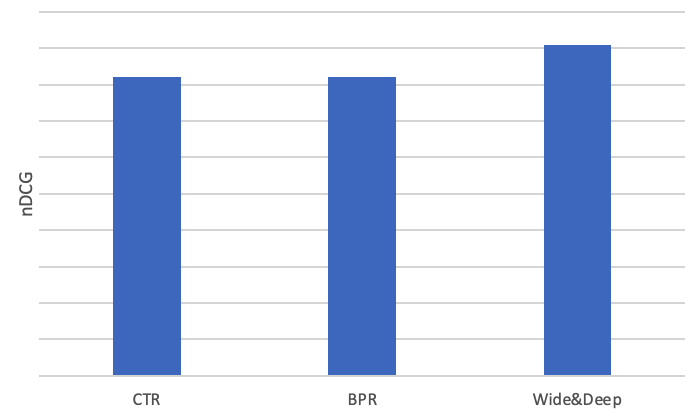 いいデータであれば、BPRとWide&Deepがもっと性能を出せ、論文の通りにCTRを超えました。
しかし、実サービスのデータでは、より一個目の実験のデータの方に近いです。ログがまだ十分に溜まっていない新規ユーザーがいつもそこにいます。従来研究のモデルそのままに実サービスに運用すれば、予想通りに効果が出ないと思います。
いいデータであれば、BPRとWide&Deepがもっと性能を出せ、論文の通りにCTRを超えました。
しかし、実サービスのデータでは、より一個目の実験のデータの方に近いです。ログがまだ十分に溜まっていない新規ユーザーがいつもそこにいます。従来研究のモデルそのままに実サービスに運用すれば、予想通りに効果が出ないと思います。
他には、計算時間の問題もあります。コンテストと違って、学習のかかる時間は更新の頻度を制限し、推論時間はレスポンスタイムに影響を与えます。より頻繁な更新と快適なユーザー体験を届けるために、計算量の検討もしなければなりません。特に、深層学習系のモデルは、どう実装すれば即時の推論ができるのは課題です。 今はまだ研究を続けています。今後のブログを楽しみに待ってください。
まとめ
本記事では、グノシーアプリのクーポン推薦の困難点と従来の推薦モデルのサーベイ結果を軽くまとめました。新卒として、大学院時代と違う目線から問題を見るのは、面白いと思います。特に自分でサーバーログから使える特徴量の洗い出しは今までのデータの前処理と違って新しい体験です。計算時間の縛りも縛りプレイみたいは醍醐味があります。この二つのところ、今まで勉強不足でしたが、早く慣れるように頑張ります。
明日はKosuke Takenakaさん(@625)がgoで書くfirehoseのlambda for data transformationの話を紹介していただきます。楽しみに待っていてくださいね!