はじめに

DRE Team の hyamamoto です.
皆さん,Spark は利用されていますか? Gunosy では Digdag + Athena によるデータ整形が増えてきており,徐々に Spark の利用は減ってきています. 思い返すと,昨年入社後の OJT も Spark から Digdag + Athena への書き換えタスクでした. 一方で,決して多くはないものの,この構成ではカバーし切れない処理もあり,そういったものに関しては Spark を用いています.
話は少し飛びますが,DRE Team では Digdag や派生するバッチ処理を実行するための Kubernetes Cluster を EKS 上に構成しています. また,一部のタスクは Kubernetes の Job として Digdag から投げることで,リソースをスケールさせつつ様々な処理が可能となっています.
しかしながら, Spark を動かすとなると EMR を利用することになり,Digdag から EMR を利用するための工夫が別途必要になります. このような背景から,管理や概念の統一化を目指して EMR から Kubernetes に寄せたいというモチベーションがこれまでありました.
そこで今回 Spark on k8s と呼ばれる Spark の機能を利用して,Kubernetes Native に Spark を実行するように構成を変更しました. 多くの記事では GKE 上で動かすのを主眼に置いたものが多いため,ここでは EKS で実際に動かす手順として比較的詳細な手順を示します. 記事全体として長くなりますが,利用を検討している人への助けになれば幸いです.
Spark on k8s について
ここでは,Spark on k8s の概要を示します.忙しい人はここだけ目を通して頂けると幸いです.
Spark on k8s とは名前の通り Spark を Kubernetes 上で動かすためのプロジェクトです. 公式の機能として盛り込まれており,Spark 実行環境のための Cluster がなくても Kubernetes 上で実行が可能となります.
詳しい内容は公式 Docs に譲ります.
How it works

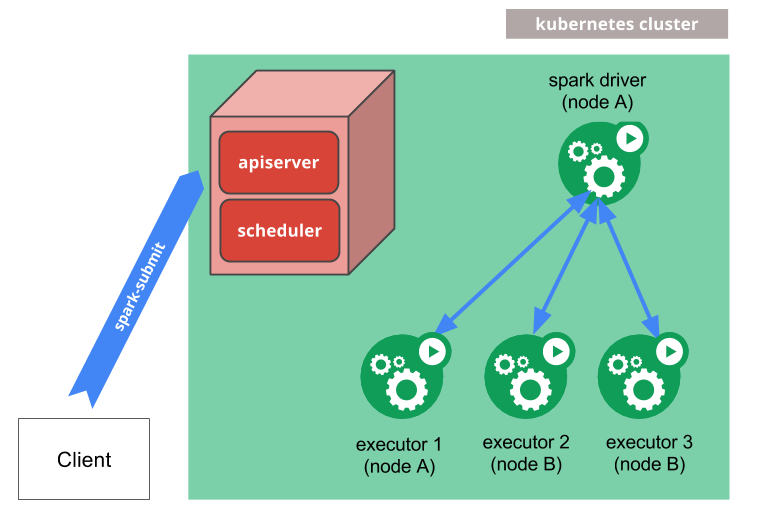{kind=link}
ここでは簡単に動作について説明します. Spark on k8s では上記図のように client が spark-submit を Kubernetes Cluster に投げ,spark driver および executor の pod を作成する構造になっています. このため,spark-submit が中で pod の定義を動的に作成し k8s cluster に流し込むというものです.
spark-on-k8s-opeartor
しかしながら,Spark 公式が提供する spark-submit では設定できる項目がまだまだ少なく,元来 yaml で記述されるような Kubernetes の設定を CLI の引数で記述するのは厳しいという課題があります. このような課題を解決するために spark-on-k8s-operator という CRD が GCP から提供されています.
spark-on-k8s-operator では SparkApplication という CRD によって Spark に対する設定を記述することができます. これによりかなり Kubernetes ネイティブな感覚で Spark の実行をすることが可能です. また,Mutating Admission Webhook (Dynamic Admission Control | Kubernetes) の設定を有効化することによって,本来,公式の方法では設定できない pod affinity なども含めて設定することが可能となります.
今回はこの spark-on-k8s-operator と用いて EKS 上で Spark を実行していきます.
メリット・デメリット
Spark on k8s を導入するメリット・デメリットは以下のとおりです
- メリット
- Kubernetes 環境がすでにあれば kubectl ベースに実行ができる
- Livy に投げて〜みたいなのがない
- フルマネージドサービスと比較してお安い
- 弊チームでは EC2 関連のコストについて 3 割ほどカットすることができた
- 監視もクラスターに関する監視で統合できる
- pod ごとにリソースの使用量も見ることが可能
- Kubernetes 環境がすでにあれば kubectl ベースに実行ができる
- デメリット
- spark-on-k8s-operator 自体の管理が必要
- β 版なので破壊的変更はありそう
- どっぷりフルマネージドサービスの機能に依存していると移管は難しい
インストール
ここでは spark-k8s-operator を EKS 上に導入し,Spark を Kubernetes 上で利用するまでの手順を記述します
概要
| Component | Version | メモ |
|---|---|---|
| Spark | 3.0.0 | |
| Hadoop | 3.2.1 | IRSA に対応するため 3.2.1 以上が必要です(aws sdk の都合) |
| Scala | 2.12 | |
| spark-on-k8s-operator | spark-operator-chart-1.0.7-2-gf87e927 | このガイドを整備した際のバージョンであり,これに従う必要ありません. |
| Feature | Available | メモ |
|---|---|---|
| spark-k8s-operator の機能 | ||
| S3 から jar を拾ってきて実行 | おおよそのチュートリアルでは 実行 Application の jar を含めたイマージを作成するような内容が多いが,今回の方法では s3 から動的に拾って利用することが可能 | |
| IAM Roles for Service Accounts (IRSA) | 権限は Application ごとに絞りましょう | |
| S3 上のデータを DataFrame API で処理 | ||
| Hive で Glue Data Catalog を メタストアとして利用 | DataFrame API ベースのものだけが対象です |
Steps
1. Build Spark Image
まず,Spark のイメージを作成します.これは公式で管理されているものが存在しないためです. なお spark-on-k8s-operator で管理されているイメージを利用するのも手ではありますが,これは GCP 向けに整備されたものなので追加の処理が必要です.
バージョンに応じた環境変数の定義
$ export SPARK_VERSION=3.0.0 $ export HADOOP_VERSION=3.2.1 $ export SCALA_VERSION=2.12
Spark のコンパイル
$ git clone https://github.com/apache/spark
$ cd spark
$ git checkout -b v${SPARK_VERSION} refs/tags/v${SPARK_VERSION}
# this command takes about 30 min
$ ./build/mvn -Pkubernetes -Dhadoop.version=${HADOOP_VERSION} -DskipTests clean package
これにより,assembly/target/scala-${SCALA_VERSION} 以下にコンパイルされた jar ファイルが作成されると思います.
なお,この Spark 3.0.0 の Build 時についてくる guava は古く不具合を起こすため,コンパイル先の guava を削除後,以下のコマンドで新しいものを拾ってきて差し替えててください.
$ curl -OL https://repo1.maven.org/maven2/com/google/guava/guava/27.0-jre/guava-27.0-jre.jar
依存ファイルの抽出
Dockerfile の作成には spark repository における以下のデータが必要です
bin/sbin/assembly/target/scala-${SCALA_VERSION}/(先程コンパイルしたもの)resource-managers/kubernetes/docker/src/main/dockerfiles/spark/entrypoint.sh
CI/CD を高速化させるためにも,これらのデータ(特にコンパイル済みの jar)は S3 などのストレージで管理しておくことをおすすめします.
Dockerfile の作成
Dockerfile は spark repository 内における resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile を参照して作っていきます.
基本的な Dockerfile の内容は上記リンク先ままで大丈夫ですが,
例外として EKS 上で動かすことを想定するため,追加で aws-java-sdk および hadoop-aws が必要になります.
おおよそ以下のような内容が Dockerfile に記述されていれば良いです.*1
ARG HADOOP_AWS_VERSION=3.2.1
ARG AWS_JAVA_SDK_VERSION=1.11.828
ARG SCALA_VERSION=2.12
ARG SPARK_VERSION=3.0.0
~~中略~~
RUN curl -fsLO https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/${HADOOP_AWS_VERSION}/hadoop-aws-${HADOOP_AWS_VERSION}.jar \
&& curl -fsLO https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/${AWS_JAVA_SDK_VERSION}/aws-java-sdk-bundle-${AWS_JAVA_SDK_VERSION}.jar \
&& mv hadoop-aws-${HADOOP_AWS_VERSION}.jar aws-java-sdk-bundle-${AWS_JAVA_SDK_VERSION}.jar \
${SPARK_HOME}/jars
また,先程抽出した依存ファイルに関しても適切に Image内にコピーしてください. Build に成功したら,実行したい Cluster が参照可能な場所にイメージを push しておきましょう.
2. Build spark-on-k8s-operator Image
次に spark-on-k8s-operator のイメージを作成します. こちらは公式配布のものがありますが,一応のためベースイメージを先程自作したイメージに差し替えるようにします.(公式配布でも動くかもしれませんが未検証) 幸い,ベースイメージは ARG で設定されているため,以下のように先程作成したイメージを渡してやれば作成が可能です.
$ git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
$ cd spark-on-k8s-operator
# 必要に応じてバージョンチェックアウト
# 変数 SPARK_IMAGE には 1. の Build 時に付けた tag を与えてください.
$ docker build --build-arg SPARK_IMAGE=${SPARK_IMAGE} .
こちらについてもイメージを push しておきましょう
3. Install spark-on-k8s-operator to the cluster
次に 2. で作成したイメージを使って spark-on-k8s-operator を EKS にインストールします.
GoogleCloudPlatform/spark-on-k8s-operator#installation を参考にしつつ helm を用いてインストールします.
なお,helm 単体のスクリプトを利用するとコード化されないため,helmfile や skaffold を利用することをオススメします.
ここでは, Values に対して以下の内容を設定します.
image.repository=${2. で作ったイメージの push 先}
image.tag=${2. で作ったイメージの tag}
webhook.enable=true
serviceAccounts.spark.create=false
あえてデフォルトの SparkApplication 向けの Service Account を発行しません. 理由としては,Service Account の権限は Spark Application によって決まるためです. よって,中央集権的な operator に紐づく Service Account は作成しないように注意します.*2
最終的に spark-opeartor の Deployment および SparkApplication という名前の CRD が存在していれば成功です.
4. Create Service Account for Spark Applications
3. で作成しなかった Spark 向けの Service Account を発行します.
IRSA を達成するため,このService Account は最終的に IAM Role と紐付けられるため,以下のように Terraform で作成すると便利です.
resource "kubernetes_service_account" "spark" {
metadata {
name = "spark"
namespace = var.k8s_namespace
annotations = {
# aws_iam_role.spark にはすでに S3 への権限などが付与されている
"eks.amazonaws.com/role-arn" = aws_iam_role.spark.arn
}
}
}
resource "kubernetes_role" "spark_role" {
metadata {
name = "spark-role"
namespace = var.k8s_namespace
}
rule {
verbs = ["*"]
api_groups = [""]
resources = ["pods", "services"]
}
}
resource "kubernetes_role_binding" "spark_role_binding" {
metadata {
name = "spark-role-binding"
namespace = var.k8s_namespace
}
subject {
kind = "ServiceAccount"
name = "spark"
namespace = var.k8s_namespace
}
role_ref {
api_group = "rbac.authorization.k8s.io"
kind = "Role"
name = "spark-role"
}
}
必要な権限は大凡以下のとおりです.
- EKS cluster の Service Account として
- pods 操作の全権限
- services 操作の全権限
- AWS の IAM role として
- IRSA のための policy: 参考
- IRSA のための OIDC provider の設定などは別途必要になりますが,ここでは触れないので参考記事などを参照して設定してください.
- 実行アプリケーションの jar を配置した S3
- 実行アプリケーションが操作するデータを配した S3
- その他実行アプリケーションが使うリソースへの権限
- IRSA のための policy: 参考
5. [Optional] Create ConfigMap
そこまで重要ではありませんが,SparkApplication のログは中々に多く破産しかねないため log4j のログレベルをデフォルトから変更することをオススメします. この際 ConfigMap を利用して log4j の config を作成する必要があるので先に作っておくと便利です. 具体的には GoogleCloudPlatform/spark-on-k8s-operator の sparkConfigMap の項目および log4j の config template を参考にしてください.
以上でインストール完了です
1. ~ 3.に対しては Cluster に対する設定4. ~ 5.の操作は Applicationに対する設定- よって利用する Application が増えたら別途設定が必要
であることにだけ留意してください.
使い方
ここまで来ると SparkApplication (CRD) を使って Manifest を作成し apply するだけになります. このため 簡単な例をもとに EKS 特有の観点やハマりポイントについてのみ解説します. また,詳しい設定内容は本家の Docs を参照してください
Manifest 例
apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-app labels: &labels app: spark-app spec: type: Scala mode: cluster image: "spark-image" # Installation の 1. で作成したもの mainApplicationFile: "s3a://${bucket}/${key}" # (1) 作成した jar を配置した S3 mainClass: FooClass arguments: - foo timeToLiveSeconds: 600 # (2) TTL, resouce を削除してくれる dynamicAllocation: # executor を動的に設定する enabled: true initialExecutors: 1 minExecutors: 1 maxExecutors: 5 sparkVersion: "3.0.0" restartPolicy: type: Never hadoopConf: # (3) IRSA で認証するための設定 "fs.s3a.aws.credentials.provider": "com.amazonaws.auth.WebIdentityTokenCredentialsProvider" sparkConfigMap: spark-config # (4): # Installation の 5. で作成したもの sparkConf: # (4): log4j の設定反映 spark.executor.extraJavaOptions: "-Dlog4j.configuration=file:/etc/spark/conf/log4j.properties" driver: cores: 1 coreLimit: "1" memory: "4096m" labels: # (5): label があると後で pod 監視が容易になる(別途設定は必要) <<: *labels version: 3.0.0 serviceAccount: spark podSecurityContext: # (3) IRSA で認証するための設定 fsGroup: 65534 annotations: "cluster-autoscaler.kubernetes.io/safe-to-evict": "false" affinity: &affinity nodeAffinity: ... # 環境によるので省略 executor: cores: 1 coreLimit: "1" memory: "4096m" labels: <<: *labels version: 3.0.0 serviceAccount: spark podSecurityContext: fsGroup: 65534 affinity: *affinity
ポイント
(1) 実行 Application 呼び出し
hadoop の s3a client を使って実行 Application を呼び出します.
また,実行 Application において S3 上のファイルを load する際にも同様に s3a:// でアクセスします.
(2) timeToLiveSeconds について
この変数を設定する事によって,一定時間経過後,自動的に SparkApplication が削除されます.よって,SparkApplication が溜まりすぎた結果 Cluster が重くなるという現象についても避けることができます. ただし,SparkApplication が実行中の場合は発火しないイベントになっていることだけ注意してください.実行時間に対する TimeOut を設定する場合は別途監視した上で,自分でリソースを削除するなどが必要になってきます. Expire の条件についてはこのあたりに実装があります.
(3) IRSA で認証するための設定
IRSA で認証をするために,hadoopConf に対して,下記のような設定をしてください.
"fs.s3a.aws.credentials.provider": "com.amazonaws.auth.WebIdentityTokenCredentialsProvider"
また,認証トークンは volume マウントされるため,root ユーザー以外の実行を考慮し以下のような設定も別途必要になります.
podSecurityContext: fsGroup: 65534
(4): log4j の設定反映
Installation の 5. で作成した ConfigMap をもとに log4j の設定をします.
本来パス的には自動的に読み込んでくれそうですが,以下のように別途 configuration を指定しないと読み込んでくれませんでした.
アップデートなどでここの挙動は変わるかもしれません.
spark.executor.extraJavaOptions: "-Dlog4j.configuration=file:/etc/spark/conf/log4j.properties"
(5): pod に label をつける
余談ですが driver や executor に対して label を設定しておくと,これらの pod の監視が容易になるのでオススメです.
実行
ここまでくれば簡単です.
$ kubectl apply -f spark.yaml
以上で Spark が Kubernetes 上で実行されます.
Kubernetes 上の動作としては次のようになります.
- SparkApplication (CRD) が作成される
1.を元に driver の pod が作成される- executor の pod が複数作成される
お疲れさまでした!
まとめ
以上 Spark on k8s を EKS 上で動かす方法でした.
やってみた感想として,
- Spark 環境の作り方
- AWS の OIDC と IRSA
- helm + helmfile による IaC
- CRD や Mutating Admission Webhook 機能
などの理解が深まり学びの多いものでした.
また,コスト面や監視面において改善があったことも,導入してよかったと感じています. まだまだ黎明期で情報も少ないためこの記事が誰かのお役に立てれば幸いです.