はじめに
こんにちはGunosy Tech Labの森本です。現在MLOps基盤を再整備しています。そこで調査した海外Tech企業の事例やMLOpsのフレームワークを紹介します。 Gunosy Tech LabのMedia MLチームではニュースアプリ(グノシー、ニュースパス、ルクラ)やクーポンアプリ(オトクル)の推薦アルゴリズムの改善を中心に機械学習を活用してアプリのサービス改善を日々行っています。過去にはチームが独立しており開発者も少数であったことから各チームがJupyter Notebook等でオフライン実験を行い、良い結果のものは本番環境に適用するためプロダクションコードを書き、レビューを行い、本番環境でA/Bテストするという流れでした。最近は開発者の人数も増え横断的にアプリのサービスを改善しているので、より効率的なMLOps基盤が求められています。
MLOpsとは
MLOpsの定義は様々あると思いますが、ここではGoogleの定義を採用します。 MLシステムにおいてCI (continuous integration)、CD (continuous delivery)、CT (continuous training)が自動化されている基盤を目指すべきMLOps基盤とします。 cloud.google.com
Googleでは状況に応じたレベルを定義しています。
- レベル0: Manual process
- モデルの実験やデプロイが手動管理されている
- レベル1: ML pipeline automation
- 実験環境、本番環境のMLパイプラインが自動化されている
- レベル2: CI/CD pipeline automation
- レベル1とレベル2の違いは実験環境から本番環境への適用がCI/CDによって自動化されている
この定義に当てはめると弊社の状況はレベル0とレベル1の間になります。
実験環境のパイプラインが自動化されていないことが課題です。
では弊社の課題を具体的に見ていきます。
実現したいこと(課題)
- 実験を効率的に行いたい=実験環境のMLパイプラインを構築し自動化する
- スケールさせたい
- 複数のパラメータ、モデル、データを扱い同時に実験を行い早く結果をみたい
- データ取得や評価などのコード共通化したい
- 実験リポジトリはGitHubで開発者ならだれでも参照可能だが、きれいに共通化されていない
- 過去の実験を第三者が試せる環境がほしい
- 実験は時間がたつにつれて煩雑になるもの
- 適切なルールを準拠することで散らかることを防ぎたい
- スケールさせたい
実現できていること(課題ではないもの)
- 本番環境へのデプロイ(CI, CD)やモデルの再学習(CT)はより洗練することはできるものの実現できている
- データ基盤周りは整っている
- 開発者はSQLを通じて自分で任意のデータを取得することができる
次に海外テック企業がどのようなMLOps基盤を構築しているのか調査しました。弊社として特に注目しているのは実験環境をどのように実現しているかです。
海外テック企業のMLOps事例
特徴
FBLearner Flowは異なるプロダクトでアルゴリズムを再利用したり、数千の実験を同時に実行できるようにスケーリングしたり、実験を管理したりすることができるプラットフォーム
実験結果の可視化
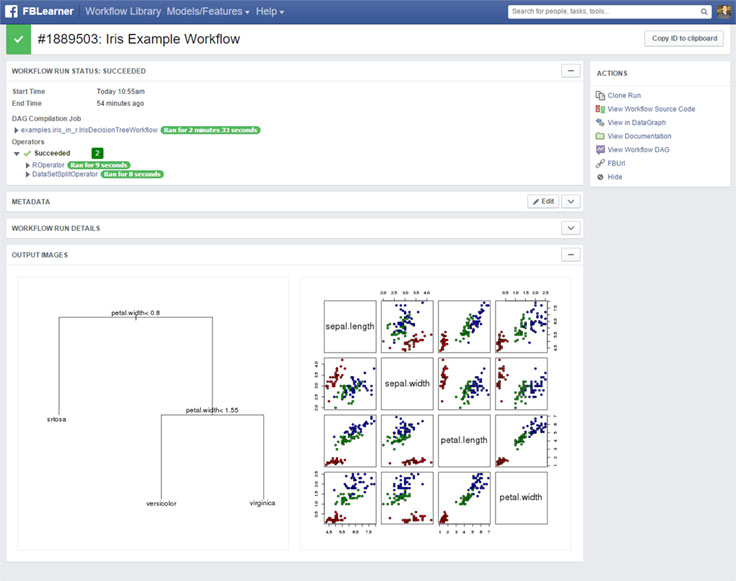
- 実験管理
- 検索エンジンはElasticsearchを使用している
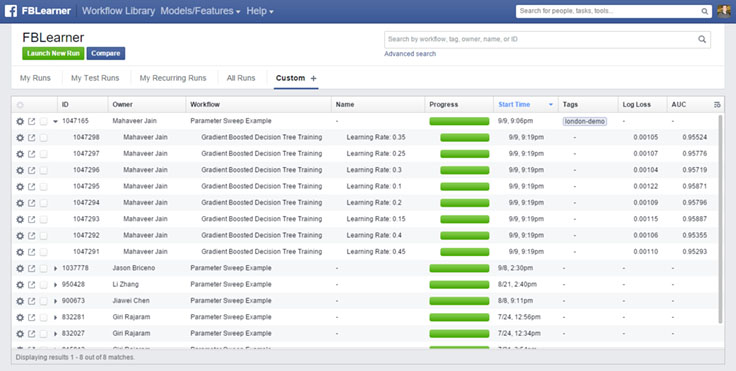
所感
- 全部入り
- 2016年の記事なので現在の仕組みがどのようになっているのか気になる
- OSSにしてほしい
Netflix
Metaflowの特徴
- データサイエンティストのためのPythonワークフローフレームワーク
- データサイエンティストがパッケージングやAPIなどのソフトウェアアーキテクチャに悩むことなくモデル開発に集中するために作成された
- AWSとシームレスに統合できるようになってる
Mesonの特徴
- スケジューリングフレームワーク
- 複数言語に対応したパイプライン
- 実験環境の管理や実験環境から本番環境へデリバリについては触れられていない
- 非OSS
所感
- Mesonは2016年の記事なのでFacebook同様現在の仕組みも気になる
Uber
特徴
- Michelangeloという基盤がある
- 当初は大規模学習バッチと予測バッチに焦点を当てていたが、特徴量をまとめたり、パフォーマンスのレポートを行ったり機能が増えていった
- Uberは配車サービス以外にもUber Eatsや自動運転など様々なサービスを展開していて、MLのユースケースは多岐にわたる

- リサーチチーム、専門家チーム、プラットフォームチームというように組織が明確に別れていて各チームの責務役割が異なる
Model developer velocityにおいて仮説検証の重要さについても触れている- プロトタイプの開発をいかに素早く回せるか、そのためにGPUクラスタなどの計算資源をシームレスに使用できる環境を実現している

所感
- 読み応えがかなりある
- Michelangeloを作っておしまいではなく、ニーズに応じてどのように進化してきたのかの歴史を学べてよかった
ここまでのまとめ
- 基本思想はどこの企業も同じ=いかに機械学習の価値を本番環境に素早く適用するか
- MLエンジニア、データサイエンティストが機械学習のモデルの開発に集中できる形に仕上げている
- パイプラインの仕組みでデプロイの簡易化や実験をスケールできるようにする
- 必要なデータに簡易にアクセスできるようにする
最後にOSSとして提供されているMLOpsフレームワークについても調査しました
MLOpsフレームワーク
MLflow
特徴
- 実験管理フレームワーク
- 実験のトラッキングが可能
- GitHubと密に連携するため、UIからどのコードで実験したかをトラッキングできる
- MLパイプラインを実現したいときはdatabricksが提供するManaged MLflowが必要
- pipでインストールできて導入は容易
- ただしcondaが必要
- しかもpipでインストールしたcondaはだめ
- 分散処理は未対応か

所感
- GitHubと密に連携してどの実験をどのコードで実施したかをUIから追跡できるのはよい
- MLパイプライン機能もOSSにしてほしい
metaflow
特徴
- Netflixが提供するMLパイプラインフレームワーク
- コマンドベース
- スケジューリング機能なし
- NetflixではMesonがスケジューリング機能を担当している
- UIからの実行やスケジューリング機能を要する場合はAirflowなどと組み合わせて使用する必要がある
- pipでインストールできて導入は容易
所感
- 使用する側としてはUI含めたスケジューリング機能もほしい
Kubeflow
特徴
- Kubernetes上で稼働する
- MLOpsが整っていない状況だと実験する側がサーバーリソースを使いすぎていないかを懸念する場合がある
- Kubernetes側で適切にリソース制限をかけておけば実験する側は実験に注力できる
- MLパイプライン
- UIあり
- 各タスクがpodごとに機能する
- Notebook Server機能あり

所感
- MLパイプライン、Notebookなど機能豊富
- Macで動作確認したがVirtualbox, Vagrantを求められるためやや大変
TensorFlow Extended (TFX)
特徴
- TensorFlowをベースとしてスケールするMLプラットフォーム
- AirflowもしくはKubeflowを利用してパイプライン機能を提供
- ドキュメントやexamples、動画、エコシステムが豊富
所感
- TensorFlowを使用している環境では有効な一方、Pytorchなどのライブラリを使用している場合は時期尚早か
フレームワークのまとめ
- 特色が異なるので課題、要件に応じたフレームワークを見極める必要があります
- Kubernetesの環境があって、パイプラインを構築したい、Notebookを使用できる環境にしたい、実験がスケールするようにしたい、様々なライブラリを使用したいのであればKubeflowが候補となります
- 簡単な実験管理という用途ではMLflowが候補となります
- もしかするとフレームワークを導入せずにML用Pythonボイラープレートで十分かもしません
おわりに
- MLOpsに関係する事例とフレームワークを紹介しました
- GunosyのMLOps環境が再整備された際はブログで紹介したいと思います
参考資料
GitHub - visenger/mlops-references: A list of references for MLOps